在 MongoDB中,其 Isolation 與 SQL標準定義的 Isolation Level不同,畢竟NoSQL注重於海量讀寫 、集群式的應用場景,自然所面對的問題也就差異很多,但也因此在面臨 Concurrency 時的讀寫保證問題,以下是閱讀官方文件並整理的結果。
Read Isolation, Consistency, and Recency - MongoDB Manual
Isolation level
正如同 SQL 不同的 Isolation 試圖在每一層解決不同的問題 (dirty read/ unrepeatable read / phantom read) 的問題,同樣在 MongoDB中也有幾種Isolation level
Read Uncommitted
Client 可以讀取那些寫入但尚未持久化的資料
- Client 會讀取到尚未 durable 的資料,以及寫入MongoDB後在該寫入Client 收到成功訊息之前
( A writes → MongoDB accept → B read A’s write → A accept success) - 如果是多行寫入的操作(如 updateMany),Client 可能會讀到更新未完全的文檔 (如果一次更新五個文檔,可能讀到三個更新後文檔,但每個文檔如果更新多個欄位,MongoDB保證不會讀取到部分更新欄位的文檔)
- Client 可能讀到之後被roll back 的數據
這是預設的 Isolation Level
在 MongoDB 4.0之後才加入 多文檔的 transaction 保證,在沒有 transaction 保證下多文檔讀取會有幾個問題
- Non-point-in-time read
A read d1 ~ d5 → B update d3 → A 可能會讀到B更新的 d3
也就是在讀取發生的該時機點沒有產生 snapshot,可以理解成 unrepeatable read - Non-serializable operations
A read d1 → B write d2 → B write d1 → A read d2
對於 d1 來說,是 A 先讀接著換 B 寫 / 對於 d2 來說,是 B寫再換 A讀;
這個情況導致兩者的讀寫相依順序剛好顛倒,所以沒辦法序列化讀寫順序 - Miss match read
**同樣是讀取中有更新發生,可能會導致更新的文檔與讀取的條件發生錯置,原本符合條件的可能更新後不符合種種
Cursor Snapshot
用 cursor 讀取在某些情況下可能會將同一個文檔返回多次,因為同期間文檔可能因為更新等因素而改變了位置
但如果文檔中有 unique key,則同個文檔僅會返回一次
Real Time Order
允許同一個文檔的多組 thread 讀寫宛如單一 thread 讀寫一般,亦即在同一個文檔中會以序列化方式執行讀寫請求
Causal Consistency
因果一致性,例如刪除符合某特定條件的文檔,接著讀取同樣條件,後者狀況依賴於前者,於是前後兩者便有了因果關係;
MongoDB 3.6+ 提供 writeConcern:majority / readConcern:majory 外加因果性的保證
- Read your writes
寫入後緊接著讀取寫入的資料 - Monotonic reads
讀取資料的結果不可以是比上一次讀取結果更早的結果
例如 w1 → w2 → r1 → r2,w2 相依於 w1,r1 這裏相依於 w2 ,那麼 r2 不可能讀取到 w1 的結果 - Monotonic writes
因果序先於其他寫入者必然先發生寫入
也就是 w1 → w2,w1 / w2 之間可能還有其他的寫入操作,但是 w1 必然比 w2 早執行 - Writes follow reads
要在讀取之後寫入的寫入事件必然發生於讀取之後
也就是 r1 → w1,則r1 必然發生於 w1 之前
Write Concern 與 Read Concern
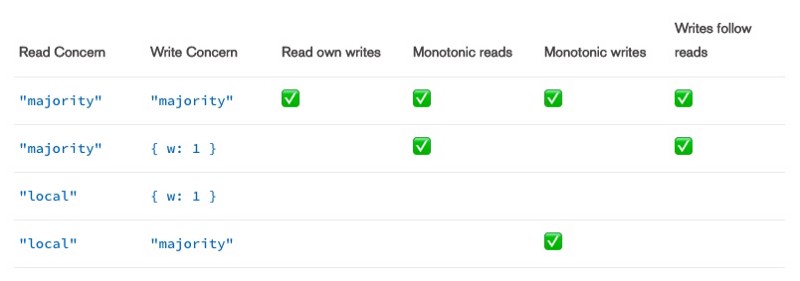 截自 MongoDB 官方文件
截自 MongoDB 官方文件
https://docs.mongodb.com/manual/core/causal-consistency-read-write-concerns/
MongoDB 在讀寫有不同的 Isolation Level可以設定,也就是 Read Concern / Write Concern,不同的Level對應不同的一致性與可用性的考量,交錯後有多種組合狀況,Isolation level 可以定義在連線 session、Transaction、單次操作
Write Concern
Write Concern 主要是指 當 Client 送出寫入請求後,Server會在什麼條件下回應Client 已經成功寫入了,總共有三個參數可以使用
- w:
寫入保證條件 - j:
Boolean,是否寫入 disk journal 後才返回 - wtimeout:
多久後發生timeout避免鎖死,0代表不需要 timeout 設計
其中 w 又有幾種選項
<number>: 對應幾個 mongod server 收到寫入請求才會回應成功訊息0代表不需要回應,但可能會回傳 network / socket 相關錯誤1預設值,寫入請求被 standalone mongod 或是 primary 收到超過 1僅適用於 replica set,也就是 primary + secondary 總共幾個收到才會回應成功majority
擁有投票權的節點*過半數都收到寫入請求,對應的 j 變數如果沒有宣告則看系統的預設值[writeConcernMajorityJournalDefault](https://docs.mongodb.com/manual/reference/replica-configuration/#rsconf.writeConcernMajorityJournalDefault "writeConcernMajorityJournalDefault")
Arbiter 雖然有投票權,但是不算在其中,因為沒有儲存資料<tag>
在設定 replica set 可以指定 tag,此處的 tag 表示寫入請求被送往符合的 replica set
Read Concern
local
最低的讀取保證,讀到的資料不保證已經被 majority 寫入且可能資料會 rollback
available
基本上跟 local一樣,只有在 shard cluster 的時候 available 是最低延遲的讀取請求,並不會更新 sharding中的中繼資料(does not contact the shard’s primary nor the config servers for updated metadata.)
因此可能會讀取到 orphaned document (某些資料已經搬移到其他chunk但是在原始位置因為錯誤或是意外shutdown導致沒有清除,需要額外清除 cleanupOrphaned
majority
保證讀取到的資料是被replica set 中的多數確認過,且不會 rollback,注意是 acknowledge 而不一定是 durable,要對應看writeConcern!
如果是在多文檔transaction中,除非 writeConcern 是 majority,否則 同在 transaction 中的 readConcern 不能提供保證。
但需要注意 majority 僅能確保讀取資料不會 rollback,但是不保證能讀到最新資料
官方建議在 primary-secondary-arbiter PSA架構下關閉 majority,因為複製不會到 arbiter,所以要達到 majority條件就是 primary-secondary 兩台都成功寫入才算成功,會給系統帶來比較大的負擔,容錯性也變差*
linearizable
基於 majority 提供更強的保證,保證寫入後的讀取都不會讀到更舊的資料,除了選擇讀取的節點外,還會去跟多數節點確認,之後才返回值,所以效能需求又高出一截;
為什麼還需要跟多數節點在確認呢?
主要是怕 network partitioning,也就是因為網路延遲而導致原本的 replica set 被分割,例如原本 3台變成 1 + 2,而 2台一組的部分因為還符合多數可以產生新的 primary,此時如果有人去讀(majority) 1那一台就可能取得舊資料,因為 1徹底跟其他節點分離;
加上 linearizable可以避免掉此問題,詳細可參考此問答 https://stackoverflow.com/questions/42615319/the-difference-between-majority-and-linearizable
snapshot
只在多文檔 transaction 中生效,文檔沒有過多敘述,但推敲應該也就是保證在同一個 transaction 中不會讀取到 transaction 之後的更動。
讀取的實例說明
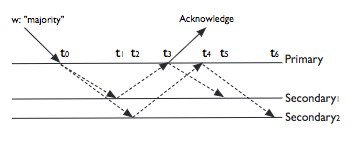 截自 MongoDB 官方文件
截自 MongoDB 官方文件
readConcern: majority
- t0 : primary 收到寫入請求,因為這時 primary 值還是 write_prev
- t1:secondary1 收到寫入同步請求,此時 primary / secondary 還是 write_prev
- t2:secondary2 收到寫入同步請求,此時值也都還是 write_prev
- t3:因為writeConcern是 majority,此時 primary 收到 secondary1的回覆,此時 primary才變成 write_new,並且回復 client 寫入成功,但是 secondary1 還是停留在 write_prev
- t4:primary 收到 secondary2 回覆
- t5:secondary1收到 primary1,此時 snapshot才更新為 write_new
- t5:secondary2 動作同上
readConcern: local
- t0:primary 此時值是 write_new
- t1:secondary1 此時值是 write_new
- t2:secondary2 此時值是 write_new
readConcern: majority 讀取時是透過 snapshot,根據此篇文章MongoDB readConcern 原理解析 指出
MongoDB 会起一个单独的snapshot 线程,会周期性的对当前的数据集进行 snapshot,并记录 snapshot 时最新 oplog的时间戳,得到一个映射表
只有确保 oplog 已经同步到大多数节点时,对应的 snapshot 才会标记为 commmited,用户读取时,从最新的 commited 状态的 snapshot 读取数据,就能保证读到的数据一定已经同步到的大多数节点。
結語
這篇主要整理與理解一些官方文件的資料與設定,並沒有什麼太重大的結論,更進一步可以看一下,條列在 Causal Consistency 下的不同讀寫保證
Causal Consistency and Read and Write Concerns - MongoDB Manual
註記
擁有投票權
在MongoDB的 Replica set中,只有以下幾種狀態有投票權 (voting node)
- primary
- secondary
- startup2:節點載入成員的設定檔正式成為 replica set的一員並開始初始化同步與索引建立
- recovering:當節點尚未準備讀取請求時,等到 client 覺得ok便會轉為 secondary,這部分沒有明說 recovering 中做了什麼
- arbiter
- rollback:當舊的 primary 因為某些因素被剔除,之後選出了新的 primary,舊的 primary 後來恢復同步發現有些寫入當初沒有同步,此時舊的 primary會選擇 rollback 這些沒有同步的資料
目前 MongoDB的 replica set最多只能有 50個成員,其中最多只能有 7 名成員有投票權;其他沒有投票權的成員可以當作備份或是讀取請求的節點。
Replica Set 容錯性問題
replica set 規定是要在超過多數的形況下才能運作,所以最低必須要有三個可投票節點才能成立,試想以下狀況
- 3台機器,可以容錯一台,需要保證 67%的機器運作正常
- 4台機器,也是僅可容錯一台,需要保證 75%的機器運作正常
這也是為什麼會推薦使用奇數台的機器;
在 PSA下,Arbiter 不能同步資料,所以 write: majority 必須同步寫入 primary + secondary,所以系統容錯就變差,同時加重機器的負擔。