{"class":"string",// The name of the class in string format
"description":"string",// A description for your reference
"vectorIndexType":"hnsw",// Defaults to hnsw, can be omitted in schema definition since this is the only available type for now
"vectorIndexConfig":{...// Vector index type specific settings, including distance metric
},"vectorizer":"text2vec-contextionary",// Vectorizer to use for data objects added to this class
"moduleConfig":{"text2vec-contextionary":{"vectorizeClassName":true// Include the class name in vector calculation (default true)
}},"properties":[// An array of the properties you are adding, same as a Property Object
{"name":"string",// The name of the property
"description":"string",// A description for your reference
"dataType":[// The data type of the object as described above. When creating cross-references, a property can have multiple data types, hence the array syntax.
"string"],"moduleConfig":{// Module-specific settings
"text2vec-contextionary":{"skip":true,// If true, the whole property will NOT be included in vectorization. Default is false, meaning that the object will be NOT be skipped.
"vectorizePropertyName":true,// Whether the name of the property is used in the calculation for the vector position of data objects. Default false.
}},"indexInverted":true// Optional, default is true. By default each property is fully indexed both for full-text, as well as vector search. You can ignore properties in searches by explicitly setting index to false.
}],"invertedIndexConfig":{...},"shardingConfig":{...// Optional, controls behavior of class in a multi-node setting, see section below
}}
每個 Class 內包含多個 Object 以 json 格式儲存,Object 內的屬性 (Property) 支援多種格式,額外有提供地理位置、日期、電話號碼(有點不解?!),其中地理位置在查詢上還支援方圓內的篩選
Class schema 是靜態的,如果要增減欄位需要透過 API 修改,而不像某些 NoSQL 是動態寫入的
物理儲存以 Shard 為單位
一個 Class 在物理儲存上有多個 Shard,每個 Shard 會包含 vector index / object store / inverted index,其中 vecotr index 目前是用 HNSW,其餘兩個是用 LSMTree 儲存
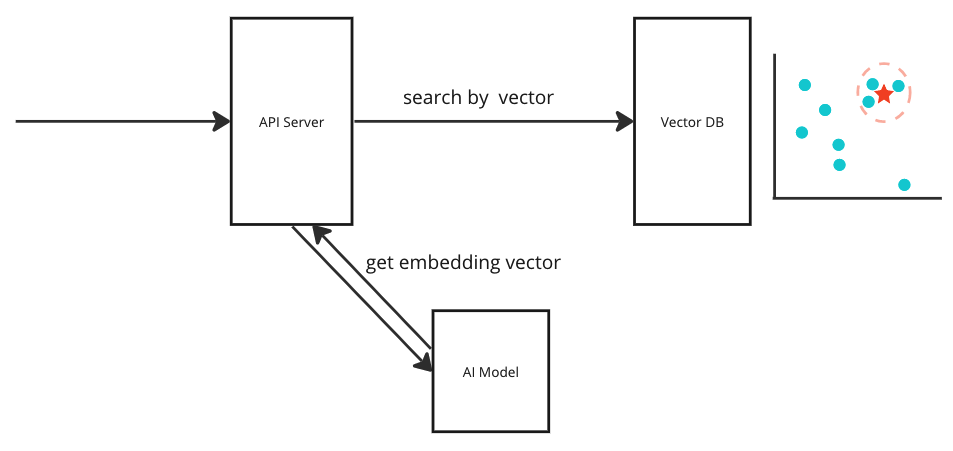
這邊我們只做文字搜尋的部分,選用 transformer 當作 AI model,可以查看不同的 modules
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
version:'3.4'services:weaviate:image:semitechnologies/weaviate:1.18.3ports:- "8080:8080"environment:QUERY_DEFAULTS_LIMIT:20AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED:'true'PERSISTENCE_DATA_PATH:"./data"DEFAULT_VECTORIZER_MODULE:text2vec-transformersENABLE_MODULES:text2vec-transformersTRANSFORMERS_INFERENCE_API:http://t2v-transformers:8080CLUSTER_HOSTNAME:'node1't2v-transformers:image:semitechnologies/transformers-inference:sentence-transformers-multi-qa-MiniLM-L6-cos-v1environment:ENABLE_CUDA:0# set to 1 to enable# NVIDIA_VISIBLE_DEVICES: all # enable if running with CUDA
建立 Class 與匯入資料
Class schema 可以主動宣告,或是讓 Weaviate DB 自動幫忙建立 (有點像 Elasticsearch),這邊建立了一個 Class 並指定 module 用 text-transformer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
client.Schema().ClassCreator().WithClass(&models.Class{Class:className,Description:"all books I have",Vectorizer:"text2vec-transformers",ModuleConfig:map[string]interface{}{"text2vec-transformers":map[string]interface{}{},},Properties:[]*models.Property{{Name:"title",DataType:[]string{"text"},},},})
objects:=[]*models.Object{{Class:className,Properties:map[string]interface{}{"title":"Hello World Blue","type":"program",},},{Class:className,Properties:map[string]interface{}{"title":"Hello World Red","type":"program",},},{Class:className,Properties:map[string]interface{}{"title":"Hello World Yellow","type":"science",},},}client.Batch().ObjectsBatcher().WithObjects(objects...).WithConsistencyLevel(replication.ConsistencyLevel.ALL).Do(context.Background())


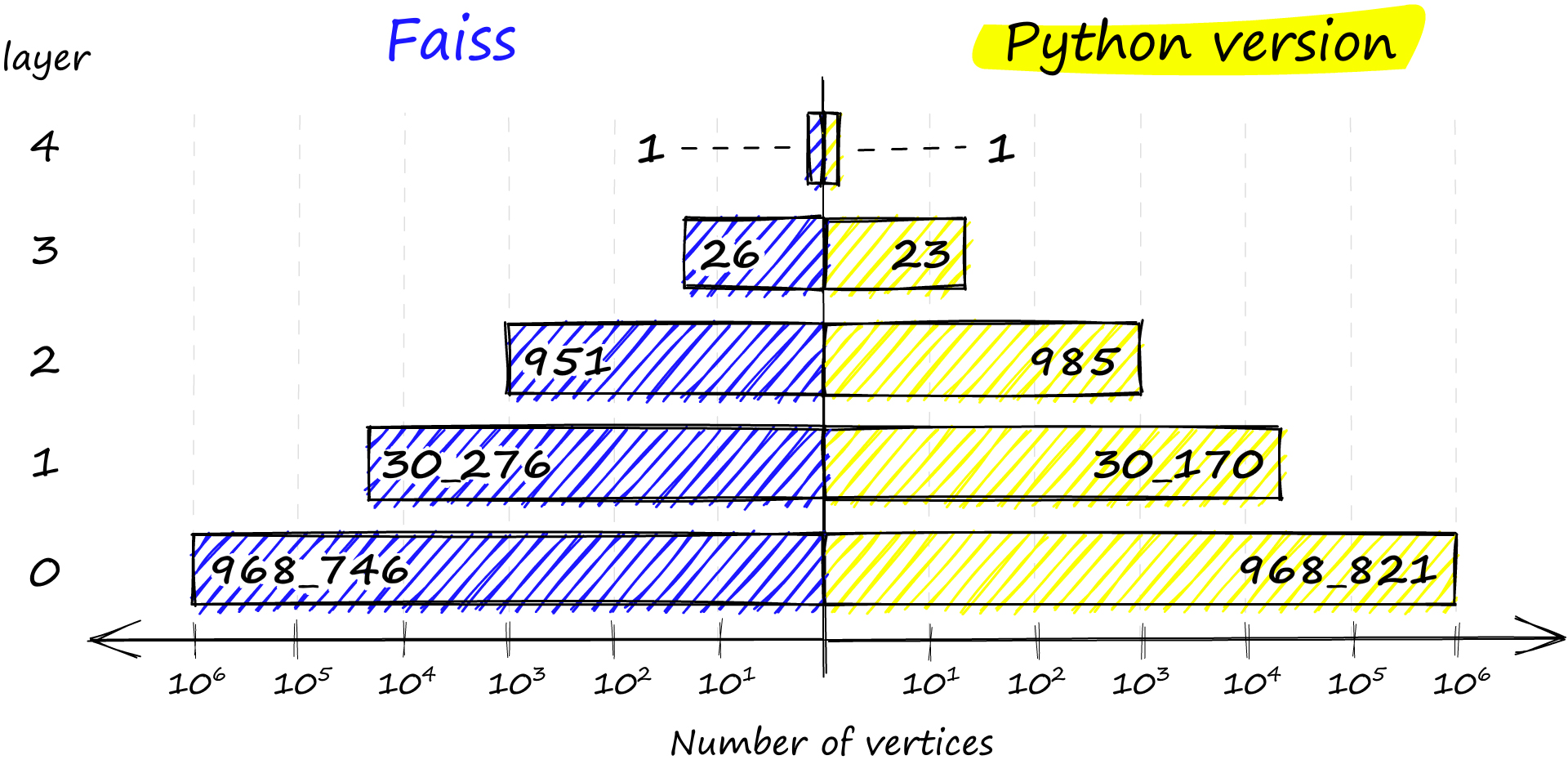
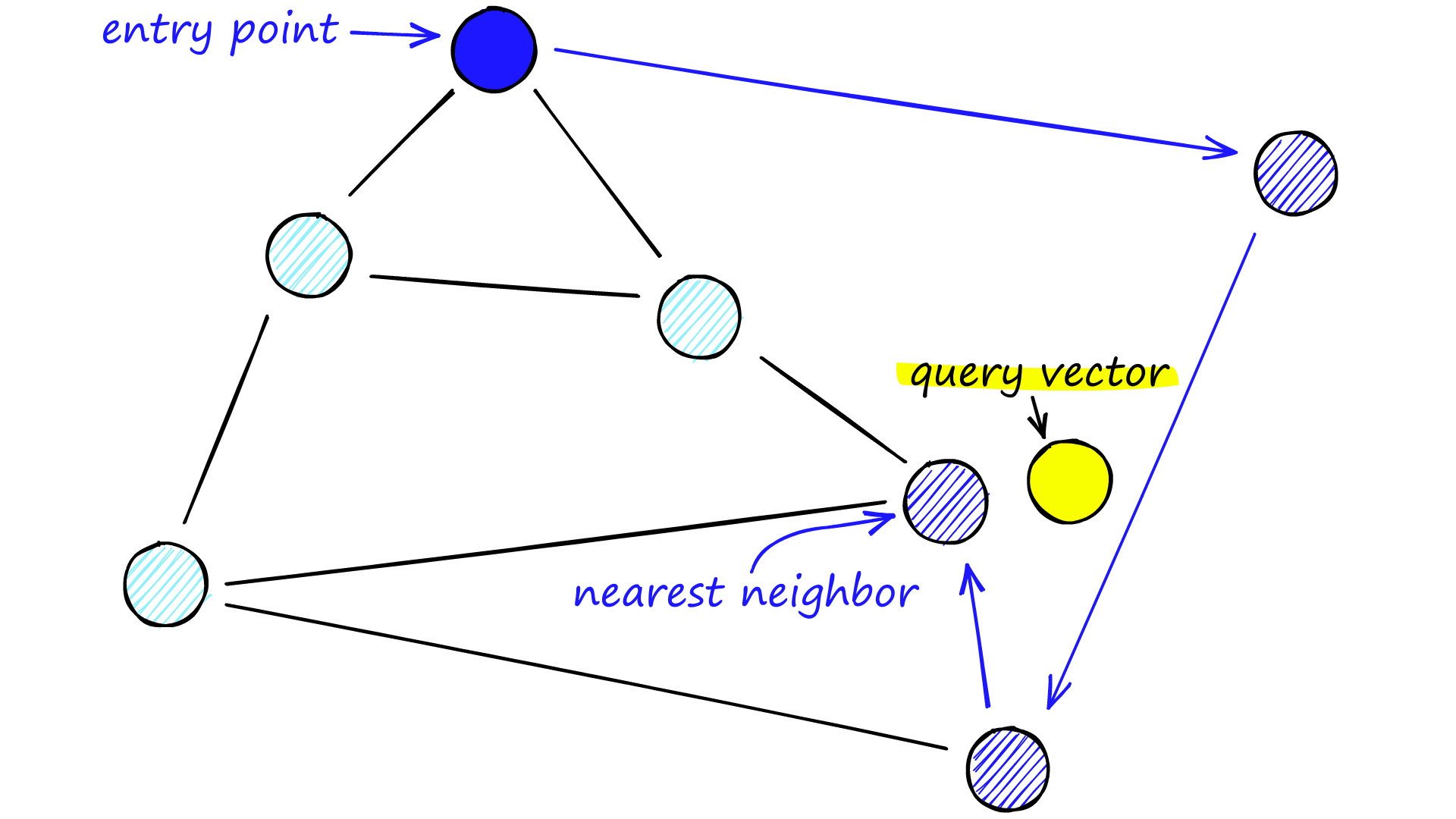 HNSW (Hierarchical Navigable Small World) 是一種 ANN 演算法,主要是借鏡 借鏡 probability skip list,透過分層查詢,先從最上層最稀疏的 layer 開始找最相近的鄰居,接著往下一層找該鄰居的最相近鄰居,一直到最底層 (layer 0)
HNSW (Hierarchical Navigable Small World) 是一種 ANN 演算法,主要是借鏡 借鏡 probability skip list,透過分層查詢,先從最上層最稀疏的 layer 開始找最相近的鄰居,接著往下一層找該鄰居的最相近鄰居,一直到最底層 (layer 0)