隨著軟體應用程式的發展,應用的侷限(bottleneck)從CPU移轉至資料的處理,資料的巨量、複雜性與改變的速度變成棘手的問題,也就是作者所定義的「Data-Intensive」資料密集的應用程式;
作者前言提及 在現今Buzzword滿天飛 Big Data / NoSQL / Web Scale blablabla,身為技術人員應該更透徹的了解資料儲存的基本觀念,這些才是永恆不變的基石;
有了清楚的概念,才能在不同的應用場景套用最適合的解法,老話一句
沒有銀彈
此書切成三大部分:資料系統的基本組成(Foundation of Data Systems)、分散式資料儲存(Distributed Data)、取得資料(Derived Data);
作者章節設計循序漸進,先定義基本用語與資料系統的設計理念與實作方式,接著加深內容且不斷的引用前面所述說的觀念;
以下是我簡單筆記本書2/3的內容,Derived Data目前有點看不懂所以就先暫時跳過 OTZ
Ch 1. Reliable / Scalable / Maintainable
再討論系統設計時,就必須先反問「想要設計出符合怎樣需求的系統」
作者提出三大軟體設計的核心
Reliable
- 運作需與使用者預期的相同
- 可以容忍用戶以非預期方式操作系統
- 效能需好到可以應付用戶需求
- 防止非授權登入與濫用
基本上就是要能夠在一定的錯誤容忍下運作正常,常見的錯誤有
- 硬體錯誤:
作者提及像硬碟的 MTTF(平均時間出錯)是10~50年,如果你的資料中心有10,000顆硬碟基本上預期是每天都會壞一顆!
=> 常見解法是:增加硬體冗余、使用RAID、額外供電設備、異地備份等 - 軟體錯誤
- 人為錯誤
Scalable
隨著用戶增加,系統需要負擔的資料也成幾何增長,所以需要系統的擴充性去回答「我們如何增加運算資源來應付增長的流量?」
再回答此問題之前,必須先知道如何描述「此刻系統的負載量」,根據不同的系統設計有不同的衡量方式,例如常見的 request per seconds / 資料庫讀寫比 / 最大同時上線人數等等,也就是要找出不同的「關鍵附載係數(Key Load Parameters)」;
衡量性能部分可以透過 percentile追蹤,分析回應速度的百分比圖,Amazon有做一個有趣的分析指出 最慢的Request意外發現是最有價值的客戶,因為往往他們的Request夾帶最多的資訊,所以也導致速度最慢;
作者舉 Twitter在2012年做用戶發送訊息為例:
Twitter 有兩個主要操作
1. 發 tweet:
用戶發送新訊息(4.6K req/sec,高峰超過 12K req / sec)
2. Home timeline:
用戶查看他們追蹤的對象消息列 (300k req/sec)
在設計上有兩種方式:
1. 發tweet時就是單純插入新的一筆紀錄,如果有用戶要讀home timeline就做 DB Join取出所有追蹤對象的訊息
2. 針對每位用戶都Cache home timeline,如果有用戶新增tweet就加到對應追蹤用戶的cache中
Twitter後來從方法一轉至方法二,原因是因為方法二的讀取timeline速度快了兩個級別,所以傾向於 花多點時間在寫入以節省龐大的讀取時間。
對於Twitter來說,用戶的追蹤數就是關鍵附載係數 **,**但每位用戶的追蹤數與被追蹤數差異十分的大,尤其是名人,所以Twitter後來採用兩種方法混用,一般用戶採用方法二,而名人則另外處理。
Maintainable
軟體最大的花費不在於建置,而在於維護,此處又拆成三個子項目
- Operability
透過一些方式可以讓軟體更好維運,例如 監控系統健康、錯誤追蹤系統、定期更新系統、隔離不同系統等 - Simpilicity
隨著系統營運不可避免功能一直加,系統也相對跟著複雜,這裡的簡易性不是說要去削減功能,而是**避免不必要的複雜性,**這裏複雜性的定義是「企圖加入實作層面的解法而跟解決問題無關」,要避免複雜性就必須透過 **抽象化(Abstraction),**例如說高階語言理當不需要理會CPU的暫存器等操作,因為語言本身已經透過抽象化隱藏了不必要的實作複雜性。 - Evolvability
需求會加、功能會改,所以系統必須保留彈性面對改變。
Ch 2. Data Models and Query Languages
這一章探討資料儲存的形式,也就是 Relation / Document / Graph Data Model,資料儲存的形式很重要,這會決定性影響了應用程式的編寫以及底層儲存方式的不同;
Relation Data Model最為常見,將資料的關聯以tuple的集合儲存(也就是SQL的row),但是現今的程式語言都是物件導向,所以要在應用程式中操作資料就必須透過ORM將資料轉換為物件形式;
這也是為什麼會有 Document Data Model,因為資料(在沒有複雜關聯下)的本身就是個文本物件,這裡的Document偏向於描述可以用 JSON / XML 結構化語言描述的資料格式,例如 履歷 {name: “hello”, age: 25, ….}。
但現實上資料本身有不同的關聯性,有One to Many 也有 Many to Many,基本上採用何種Data Model可以從資料集多對多的關聯性複雜度來決定;
如果資料僅有少部分多對多關聯,可以選擇採用Document Data Model,因為相對應用程式的代碼比較好寫,不需多一層ORM轉換、少有的多對多可以用應用程式代碼自己實踐Join功能;
如果注重物件的多對多關聯性則可用 Relation Data Model;
如果物件的關聯性相當複雜可以考慮 Graph Data Model,這也是我第一次接觸到此觀念,資料模型改以圖形化方式呈現,資料可分成vertice與edge,vertice比較像是儲存單體的資料,而edge則儲存vertice間的關係,透過圖形化的特性可以表達相當複雜、遞迴的關係,這部分可以參考我之前嘗試 neo4j的筆記。
當然上述只是單純以資料關聯與對應的模型來衡量,現實的技術採納需要有更全面通盤的考量。
這一章比較是在講古,把過去曾出現過的資料模型與對應的Query語言都稍微帶到。
最後筆記一點蠻有趣的觀點,作者提到 Document Database都會被誤稱為 schemaless,但其實更準確說法是 schema-on-read,雖然DB沒有顯性的資料欄位,但是在應用程式讀取時一樣會有資料的架構,對應的是Relation Database的schema-on-write;
schema-on-read有點像是動態語言,資料的檢查在應用程式本身;而schema-on-write像靜態語言的型別檢查,在寫入時就先檢查了。
Ch 3. Storage and Retrieval
這章節算是我覺得最有趣的一章,主要談到資料庫底層如何將資料存入硬碟中,以及如何快速的透過索引 Index 從硬碟取出資料;
首先作者用shell script編寫最簡單的資料庫
db_set () { echo “$1, $2” » database}
db_get () { grep “^$1,” database | sed -e “s/^$1,//” | tail -n 1}
$ db_set 123 ‘{name: “123”}’
$ db_get 123
採用類似 CSV格式的 鍵-值儲存,將新的資料不斷append到文件上,最後搜尋時從文件最末的資料開始找起;
這樣寫的效能很好,因為單純append資料速度非常快,但是讀取則需要O(n)的時間;
為了增加讀取的效能,我們可以建立索引,在記憶體中用Hash Table資料結構,儲存鍵對應欄位在硬碟的儲存位置,加速讀取的效能。
雖然這看起來很簡單,但實際上卻也有資料庫是採用此設計方式,如 Bitcask。
先前提到這種做法是不斷將新資料append到硬碟文件上,即使同樣的鍵也是,但是這樣文件總不能無止盡的增加下去,所以會有所謂的 compact process 壓實程序,也就是重整舊的文件,將冗余重複的鍵去除只保留最新的紀錄,減少不必要的過時資料儲存空間。
但上述方式有兩個缺點
- 索引必須小於記憶體總量否則性能會很差
- 不支援範圍讀取
Sorted String Table
 圖片來源:https://tech.liuchao.me/2017/11/ddia-3/
圖片來源:https://tech.liuchao.me/2017/11/ddia-3/
所以後來有提出新的作法 Sorted String Table (簡稱 SSTable),差別在於索引改透過 依照字串順序排序後的資料結構儲存,這有點像是字典索引,當我們要查一個單字 hello 我們可以透過前後的字去找到相近的位置;
所以如果在記憶體中所以只有 he / hola,那我們至少知道 hello 勢必在此兩個位置中間,透過 順序讀 sequential read 可以非常快的在硬碟中找到資料。
作者強調 順序讀寫對於硬碟的效能有很大的幫助,即使是SSD
B Tree
但是SSTable並不是最常用的資料系統儲存的方式,而是B Tree,B Tree是個平衡二叉樹,母節點紀錄多個區間值與對應的子節點,每個子節點則紀錄一段連續值。
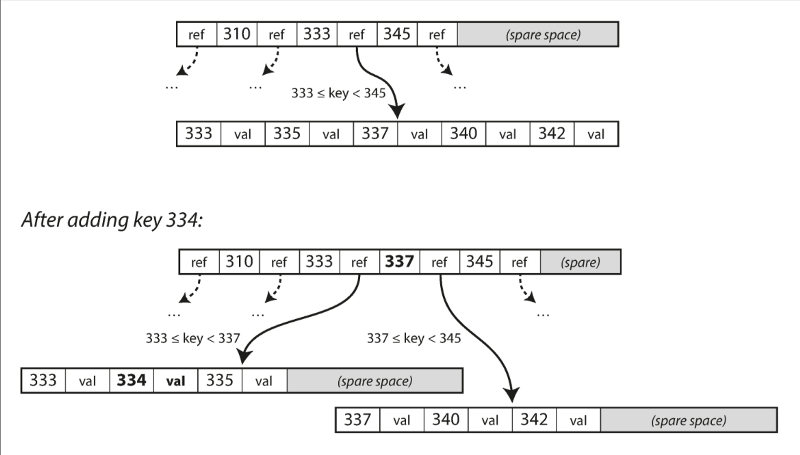 圖片連結:https://tech.liuchao.me/2017/11/ddia-3/
圖片連結:https://tech.liuchao.me/2017/11/ddia-3/
在儲存方式上不是採用append only,而是將儲存空間切割固定大小的 Page,並把節點的資料放入,如果有新的資料產生會覆寫舊的Page,這點與SSTable大大不同。
在實作上,B Tree因為會先將Page資料暫存在記憶體中,為了避免資料遺失會在資料寫入時先將資料紀錄到append-only 的WAL(Write-Ahead Log),所以一筆資料寫入其實會有兩次寫入硬碟動作。
B Tree 對比 SSTable 好處在於
- 資料冗餘少
- 找尋不存在的鍵值比較快(SSTable必須查完所有舊資料才可以確定)
- 不需要 compact process去重整資料,作者提到雖然 compact process通常在背景執行,但你永遠無法預期何時系統會爆量,也就是說好死不死大量讀寫時卡到系統在 compact process就欲哭無淚,相對來說 B Tree的系統附載比較可預期;
SSTable好處在於 B Tree切割Page容易有空間的破碎化與浪費,且部分資料更新也必須更動對應的Page;
Column-Base
一般資料庫在OLTP中都是以row-based為導向的;
但是在OLAP中,我們常會將多個DB資料彙整到統一的資料倉儲中,所以資料量非常龐大,且每筆request也都要運算非常大量的資料,這時候有個新的做法以column-base儲存資料,這樣最大好處在於同一個column通常資料重複性高,例如顏色就那幾種、產品ID可能也會重複,這種特性可以使 資料壓縮 得到非常好的效果;
但缺點就是寫入很麻煩。
在底層紀錄上,B Tree無法套用在壓縮欄位上,因為索引是紀錄row-based的鍵,所以多個column欄位更動會導致過多的Page都要一并刷新;
所以會採用 SSTable當作寫入硬碟的資料儲存方式,每次寫入都產生新檔案。
Ch 4. Encoding and Evolution
在系統的演進上,需要注意相容性問題,可分成
・向後相容:新的code可能讀取到舊資料
・向前相容:舊的code可能讀取到新資料
程式在處理資料上會有兩種形式
一種是 in memory,像是 object / array / int等,主要是方便CPU做運算;
另一種在需要寫入檔案或是透過網路傳輸時,需要重整成字串的形式,也就是encode
常見的 encode形式有非常多種,包含JSON / XML /CSV,為了讓資料可以用最小容量傳遞,作者介紹了數種基於JSON的encode / decode技術,在encode的過程中要注意資料格式與型別需要可以decode。
原本JSON原始資料 66 bytes,透過不同的binary encode技術最終可以壓縮到 34 bytes!
下集
技術筆記 Designing Data-Intensive Applications 下,第二部分主要探討分散式儲存資料會遇到的問題與解法,分散式系統有幾大優點