上集:Designing Data-Intensive Applications 上
隨著軟體應用程式的發展,應用的侷限(bottleneck)從CPU移轉至資料的處理,資料的巨量、複雜性與改變的速度變成棘手的問題,也就是作者所定義的「Data-Intensive」資料密集的應用程式。
第二部分主要探討分散式儲存資料會遇到的問題與解法,分散式系統有幾大優點:
- Scalability:
大幅增加系統的乘載能力 - Fault Tolerance / High Availability(HA):
當單一節點失效時,不影響系統的運作 - Latency:
如果用戶散佈全球,可以透過多節點部署使用戶地理位置最近的資料中心,降低網路延遲
Ch5. Replication
Replication 也就是將相同的資料透過網路複製到多台機器上,有幾個好處
1. 讓用戶可以取得地理位置最近的資料
2. 即使部分機器失效,系統也可以繼續正常運作
3. 增加機器 讀 的負載能力
在架構上有三種 Single-Master / Multi-Master / Leaderless,Replication帶來許多好處,但是在系統實作面會有取多的衡量,例如說複本是要同步還是非同步、如何處理錯誤的複本節點、最終一致性的曲解、read-your-writes、monotonic-reads保證等問題。
Leaders and Followers
每個擁有資料庫備份資料的節點稱為 replica,為了讓每筆寫入都可以被同步到replica上,常用的架構為 leader-base,也就是Leader 負責資料的寫入,並將資料同步到 Follower中保持同步。
這種replication架構被廣泛使用,包含Oracle / PostgreSQL / MySQL / Kafka等。
Sync and Async
當Leader接收到寫入,這時候要決定說是否等到同步完全部的 follower才回傳成功,如果是全部 follower說成功才成功便是 Sync,若非則 Async,也可以設定超過某數量 follower 變成 Semi-Async;
Sync好處是確保follower都擁有最新的資料,避免用戶在follower讀取到過期資料,但缺點就是如果一個 follower卡住了就會阻擋整個系統運作,系統容錯能力就大幅下降;
Async好壞處則剛好相法,寫入回應速度快,系統容錯好但用戶可能會讀取到過期的資料。
通常來說Leader-base系統都是以Async為主,因為讀取過期資料這點後續有其他方式可以彌補。
Handle Node Outages
當節點出錯要重新恢復時,會有不同的狀況,又可拆成 Leader / Follower來處理
Follower出錯要恢復或是加入新節點比較容易,只要資料記錄有追上Leader最新資料即可
但是Leader出錯就非常麻煩,必須要先 判定Leader死亡(通常透過Timeout) -> 選出新的Leader -> 整個系統承認新的Leader,並將寫入請求轉導到新的Leader上,這裡會有幾個容易出錯的地方
例如說 舊的Leader如果是採用Async,有可能會有部分寫入尚未同步到備份中所以會遺失,在Github採用MySQL案例中就發生過掉資料結果 Primary Key重複的現象;
又或是程式沒設計好,意外選出多個Leader,產生人格分裂(Split brain);
Timeout設定也很重要,太短會導致網路波動就造成不必要的Leader切換,太長則遺失的資料可能會很多,這部分很麻煩;
基於這些理由,作者提到現在有蠻多公司都採用人工處理的方式。
Implementation of Replication Logs
- Statement-based replication
最簡單的方式是直接將每筆寫入都pass到 replica上,但這會有幾個壞處,如 NOW() / RAND()等函式會因為執行的時候值而有所不同、Auto-Increment也會有所差異,此外還必須保證複製的過程寫入資料順序必須相同。 - Write-ahead log (WAL) shipping
將WAL的資料直接複製到replica就不會有上述的問題,但缺點是log相當底層,也就是會跟系統的儲存引擎嵌套很深,跨系統不易。 - Logical (row-based) log replication
Problems with Replication Lag
- Reading Your Own Writes
當用戶更新資料到Leader上,如果該用戶馬上需要讀取該筆資料,可能Follower還沒有收到複製回傳了過期的資料;
解決方法有
透過應用程式追蹤時間,當在更新後的一定時間內從Leader讀取資料、
用戶紀錄更新資料的時間,由資料庫確保從replica取出正確的資料 - Monotonic Reads
當用戶從多個replica讀取資料,可能某些replica同步比較慢導致用戶讀取多次資料卻不同;
可以綁定用戶在同一個replica讀取資料,避免不一致的資料狀況出現。 - Consistent Prefix Reads
同樣是因為replica同步有時間差,用戶可能會讀到順序錯亂的資料,例如問題勢必在答案之前出現(有問題才能有回答)
Multi-Leader Replication
多Leader的架構系統容錯性更好、寫入的性能也可以提昇,但缺點是資料衝突的情況會很多,當發生衝突時很多時候必須由應用程式來解決。
Leaderless Replication
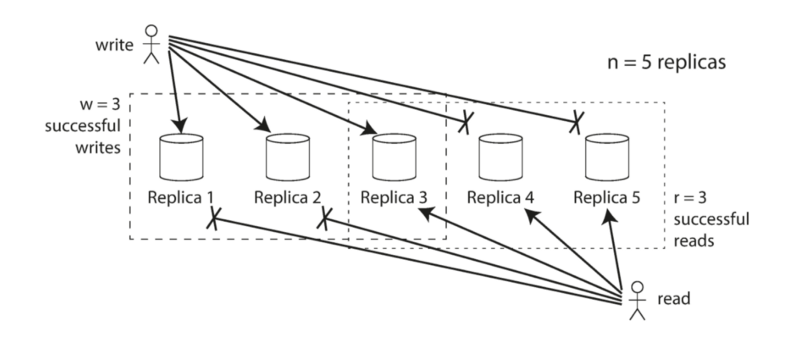
寫入和讀取都一次使用多個節點,透過量來保證資料的正確性與系統容錯性,例如總共有5個node(n),只要我們可以寫入3個以上節點(w)與讀取時讀到3個節點以上(r),在符合 w + r > n的情況下,就可以保證會讀取到最新的資料,此時系統可以容忍 n-w 個節點失效。
 https://tech.liuchao.me/2017/12/ddia-5/
https://tech.liuchao.me/2017/12/ddia-5/
Ch6. Partition
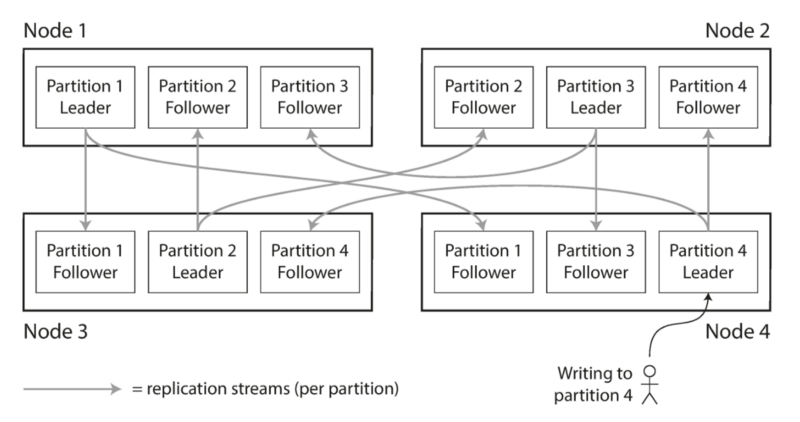
Partition分片主要是提升系統的Scalability,當大量的資料可以被平均分散到節點上,寫入和讀取「理論上」就可以隨著節點數成線性成長;
在實作上,Partition常與Replication做搭配,將資料分片並複製到其他節點上增加容錯空間
 https://tech.liuchao.me/2017/12/ddia-6/
https://tech.liuchao.me/2017/12/ddia-6/
有個良好的資料分片機制很重要,如果分片的方式不夠號,如遇上 hot-key產生歪斜skewed,導致資料不平均分散到節點上,會導致系統的性能無法得到顯著的提升,以下有兩種常見的分片機制
Partitioning by Key Range
一種常見的做法是將 Key排序並將某連續段的Key分片,這種做法好處是簡單實作、如果要範圍搜尋資料很方便;
缺點是容易會有 hot-key的問題。
所以在套用上需要特別注意應用程式本身的資料Key特性,例如說感測器收集系統,採用 timestamp 當作key可以使後續日期範圍查詢非常容易,但缺點是當天的寫入都會集中在同一個partition上;
可以考慮改成用 感測器編號,這樣寫入就可以平均分散,但相對就變成範圍讀取比較麻煩。
Partitioning by Hash of Key
可以透過 hash function將key轉成可平均分散的雜湊值,好處是寫入可以更平均分散,但缺點就是失去了範圍搜尋;
Cassandra嘗試透過組合Key來融合上面兩種方式,Key的前半段用Hash決定partition位置,partition中則依照Key的後半段排序增強範圍搜尋;
例如說(user_id, update_timestamp),透過user_id分散用戶的資料,但如果有需要取得某用戶的範圍資料更新就可以用update_timestamp。
Partitioning and Secondary Indexes
先前提的是透過 Primary Key,但如果要查詢 Secondary Key就會遇到不同的問題,例如說 汽車資料是 {carId , name , color}等,主鍵是carId並依此來分片,但如果用戶要查詢 color = ‘red’的車子就需要另外處理
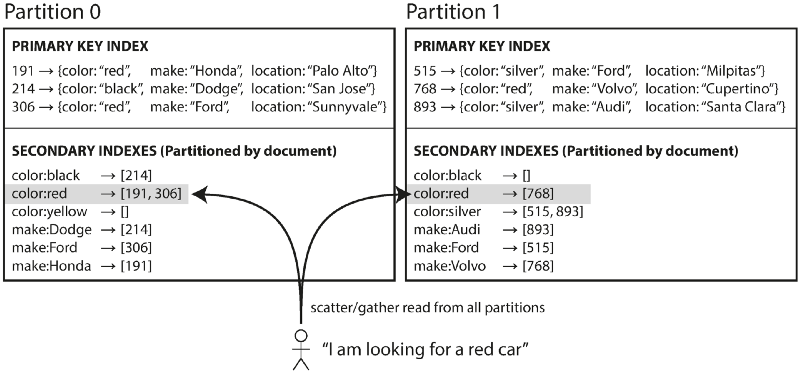
Partitioning Secondary Indexes by Document
在個別partition中自行維護各自資料的 Secondary index table,所以用戶的讀取請求需要送到每個partition中並整合,也就是 scatter /gather。
缺點就是讀取效率很差,因為可能某些partition回復比較慢整個請求就會被卡住。
 https://tech.liuchao.me/2017/12/ddia-6/
https://tech.liuchao.me/2017/12/ddia-6/
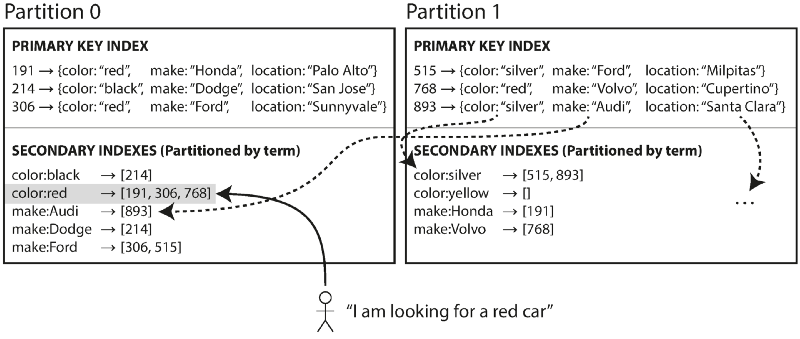
Partitioning Secondary Indexes by Term
與其個別partition分別維護Secondary index(local),可以將相同的Secondary index紀錄統一儲存在某特定partition中,透過讀取該紀錄,再去所有紀錄所在的partition讀取資料即可。
至於該筆 Secondary index要記錄在哪可以透過前述的兩種方式分散到不同node上。
 https://tech.liuchao.me/2017/12/ddia-6/
https://tech.liuchao.me/2017/12/ddia-6/
這種方式提升讀取的效能,但缺點是寫入變得十分複雜,修改單一筆資料需要同步更新不同partition中的 Secondary Index,這在分散式中會有很多隱藏的問題。
Rebalancing Partitions
如果系統附載增加,可能會需要增加 partition的機器或是移除出錯的機器等,這時候會需要重新調整partition,將資料重新平衡到所有機器上。
平衡的方式有
- hash mod N:
直接把 hash key mod {所有機器數}即可,但缺點是增加一台機器就會有大量資料需要搬移,造成不必要的負擔 - Fixed number of partitions:
將所有資料切成很多份,並平均分散到機器上,例如說 10台機器可以將資料分成 1000份,平均每台負擔 100份資料;
此時如果有新機器加入,這10台機器每台抽9~10份搬移即可,如果要移除舊機器反之;
這種方式有效降低不必要的資料搬移。
Dynamic partitioning
使用 Key-range partition不太方便,如果一開始設定錯誤,會導致資料太過集中於部分節點,如果要重新設定又會很麻煩;
所以某些資料庫(HBase、RethinkDB)內部提供動態分割的方法,當發現 partition資料超過某個size,會自動分割並把資料分成兩個partition;
如果資料大量刪除,也會自動合併成單一個partition;
每個partition分散到一個節點上,而一個節點可能儲存多個partition。
Dynamic partition可支援 key-range partition和 hash-key partition。
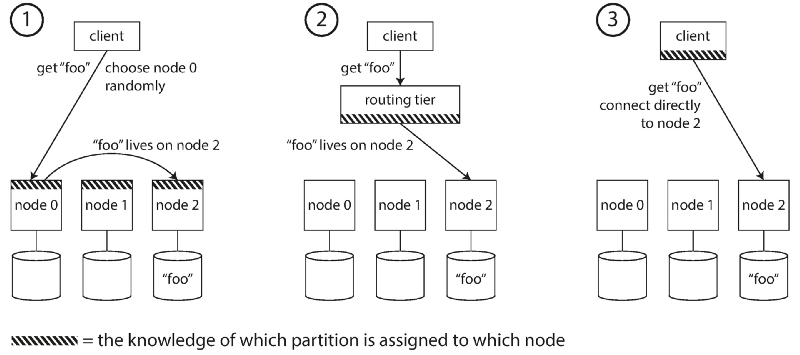
Request Routing
當用戶要發送請求,如何得知該往哪個節點發送呢?
這個問題通稱為_service discovery_ ,任何透過網路的軟體都會遇上此問題,尤其是分散式系統。
主要解法有三種方式,
client隨機發送請求到某節點,每個節點都有分片依據的紀錄;
統一一個負責routing的節點;
client端自行判斷紀錄分片的依據。
Ch8. The Trouble with Distributed Systems
Faults and Partial Failures
分散式系統傳遞資訊都是靠網路,但網路的本身是不可靠的,所以分散式系統最大的疑慮便是會有部分錯誤的產生,在某些時刻我們無法得知操作是否完全成功,所以在設計上必須考量這一點,設計出可容忍錯誤(Fault-Tolerance)的系統。
Unreliable Networks
談論一些網路的不可靠性,對比Telephone circuit 用硬體與固定頻寬的連線方式傳輸資料,TCP為了增進總體使用量會有flow control導致傳輸速度無法估測。
Unreliable Clocks
時間在電腦系統扮演重要角色,大致有兩個時間屬性 區間(Duration,如計算request時間)、確切時間(points in time,錯誤的時間log),再分散式系統中時間很tricky,因為溝通不是即時的,透過網路傳遞訊息會產生不可預測的延遲;
再者每台電腦都有各自的石英震盪器計算時間,因為各種物理性質上的差異導致無法完全精準同步每台電腦的時間。
Monotonic Versus Time-of-Day Clocks
- Time-of-day clocks(又稱 wall time):
返回日曆時間,通常是透過NTP同步時間,但如果電腦時間太快或太慢,同步之後可能會產生時間跳躍,產生一些後遺症(如資料庫寫紀錄的跳針導致資料不一致) - Monotonic clocks:
適合用來測量時間區間,「實際上他指的是系統啟動後流逝的時間,這是由變數jiffies來紀錄的。系統每次啟動時jiffies初始化為0,每來一個timer interrupt,jiffies加1,也就是說他代表系統啟動之後流逝tick數**」
**(出處:[Timer学习]wall time和monotonic time)但也因為如此,所以跨系統間比較Monotonic clocks是沒有意義的。
Timestamps for ordering events
假想系統有2個Node,當兩個客戶A、B同時對同一筆資料做改寫,但是A的Request先到Node 1而 B先到Node 2,再處理併發時分散式系統通常採用LWW(Last-Write-Win),所以更新後Node 1與Node 2資料就會不同步
Process Pauses
試想一個危險的情況,資料庫採用Single-Leader架構,Leader需要固定一段時間通知所有Follower Leader還活著,但如果Leader的執行卡住了過一段時間沒有通知,其餘Follower選出新的Leader後同時舊Leader復活,產生了雙Leader的分歧局面
在以下情況會產生程式執行被無預期卡住,如垃圾回收(GC),這會導致程式運作直接卡死直到垃圾回收結束;
在虛擬機中VM也有可能被暫時終止執行、又或是在CPU切換任務時系統負載過多而延遲等等因素
Response time guarantees
上述問題產生於 應用程式不知道執行時會遇到怎樣的突發終止狀況,所以如果可以保證突發終止的時間是可預測的,就可以透過設計避免問題,但問題就是如何保證回應時間?
RTOS(real-time Operating System)保證CPU的時間切割是固定的,所以可以得知最糟狀況應用程式會被終止多久;
但RTOS開發很貴,通常用於高度安全的系統設計如飛行系統,而且RTOS會限制應用程式可用的Library、寫法等,不適用於一般資料庫系統。
The Truth Is Defined by the Majority
分散式系統中,每個節點只能透過網路收發資料來確認彼此的狀態,但有時候節點運作正常但在與其他節點的網路溝通上出了問題,或是遇上GC整個節點卡住等,就有一樣會被其他節點誤認為「死亡」
正因為分散式系統解決了單一節點失效的問題,失效的決定則依賴多數的節點的決定。
Byzantine Faults
先前描述都是以節點失效為主,但如果節點會「說謊」呢? Byzantine Generals Problem 拜占庭將軍問題即是描述多節點在不知道彼此的情況下如何確保叛徒不會影響正確性
結論大致是只要出錯的結點不超過 1/3即可保證整體的正確性。