以下介紹如何使用 Linux Kernel 內建的工具 tc ,完成
- 網路流量管制,當一台主機上有多個網路服務,希望可以分配不同的網路頻寬、封包傳送的優先序等
- 模擬惡劣網路環境下的狀態,例如封包延遲、隨機性掉封包
環境則是在 MacOS 用 VM跑 Ubuntu 16.04。
背景知識介紹 Network Layer
tc 是基於網路分層中的 Network Layer 網路層進行封包的控制,針對封包的 ip 內容進行篩選與控制。
網路層,主要關注於如何將源端的封包透過路由器,一步步(hop)正確的傳送到接收端,中間的路由算法等略過不談,這邊主要關注於壅塞控制與服務質量
壅塞控制 ( Congestion Control )
Congestion 壅塞是指 當主機接收的封包量增加,大於發送的量,此時會被暫存於 Buffer緩存區當中,但如果封包量填滿了緩存區,就會遺失部分封包,網路也開始壅擠。
避免壅塞的方式有幾種
- 增加網路處理的能力
- 流量感知
主動將封包繞開壅塞區域,走其他利用率較低的路由器,這會需要修改路由算法,將帶寬、傳送延遲等都一併放入 link state routing 的權重分配,決定封包該送往哪個路由器 - 准入控制
如果發現負載過高,拒絕新的連線建立 - 流量調節
當路由器發現有壅塞的可能,可以主動發出訊息,再封包上標記,又或是傳送 choke package ,告知發送者應該要降低發送的速度 - 負載脫落
如果路由器來不及處理封包,為了避免壅塞會直接丟棄封包;
做法有 RED( Random Early Detection),當某個暫存區超過某個閥值,就會開始隨機丟棄封包,此時發送方就會意識到需要放緩發送速度。
服務質量 (QoS,Quality of Service)
除了壅塞控制外,應用程式對於網路的要求也會有所不同,例如說大型文件需要較大的帶寬,但是延遲性與網路抖動沒這個敏感;
但相對的影音頻直播,對於網路抖動就非常敏感,或許你可以接受一個影片穩定 delay 10秒鐘開始,但無法接受播到一半卡頓。
服務質量有兩種類別
- Integrated Service (綜合服務):
在封包傳送的路徑上,所有的路由器都保留一定額度的資源,形成專用端到端的數據流,就好比公車專用道就只能由公車行駛;
好處是能夠很穩定的服務質量,但缺點就是需要非常龐大的資源,且效率不高,具體協議可以參考 RSVP,但這因為難度過高幾乎沒有實踐。 - Differential Service (區分服務):
對比於綜合服務提供整段網路的服務質量,區分服務僅提供單個路由器的服務質量,也就是在每一次的 hop 間由該路由器保留資源(Per Hop Behavior),等到下一跳再由下一個路由器預留資源;
在 IPv4 的封包中,header 包含一個欄位 ToS( Type of Service),共 8 bits,前 6 bits 表示服務類型,後 2 bits 表示壅塞訊息。
為了提供服務質量,路由器必須決定封包發送順序( Packet Scheduling )以及控制流量(Traffic Shaping 流量整形) 的功能
Traffic Shaping 主要是針對突發性流量所採取的攤平流量方式,避免一次性塞滿緩存區導致封包掉落,常見的方式有兩種
- Leaky Bucket
有一個漏洞的桶,桶的尺寸與出口的最大流速固定;
只要上方有水注入,桶就會自動從出口出去,如果注入速度高於出口流速,就會開始在桶中累積,如果滿了就溢出。

https://www.geeksforgeeks.org/leaky-bucket-algorithm/
2. Token Bucket
桶子內改存放 Token,如果桶子滿了就不再放 Token;
如果此時有 packet 要發送,就必須從桶子中消耗一個 Token,如果沒有 Token 則 packet 不能發送。
對比 Leaky Bucket優點在於
- Leaky Bucket 桶子滿了會開始丟封包,而 Token Bucket 則是丟棄 Token
- 當流量低時,Token Bucket 有機會可以累積 Token,等到高峰時一次性使用掉,而 Leaky Bucket 無法做資源的保留
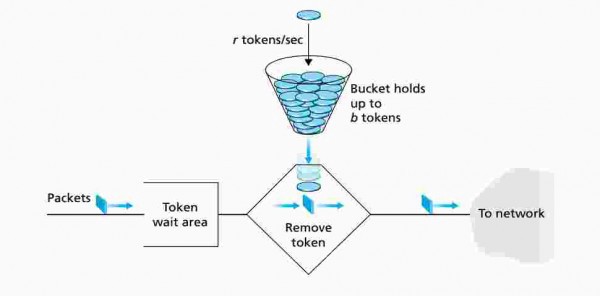
https://gateoverflow.in/39720/gate2016-1-54
Packet Scheduling 當路由器一次收到多個服務質量請求的封包時,會需要 packet scheduling 機制處理發送的先後順序,最基本的就是一條 FIFO 的Queue,所以的封包都按順序排隊發送,但是這無法提供良好的服務質量保證;
另一個是 Fair Queueing (公平隊列),每個 data flow 都獨立一個 queue,路由器以輪播的方式,輪流發送封包;
在此之上還有 WFQ (加權公平隊列),每個 Queue 權重不同,權重高的發送頻率會高於權重低。
小結:Network Layer 提供壅塞控制與服務質量的控制,而服務質量下流量整形與封包調度機制的實作,也就是後續要用 tc 控制的部分
常用網路指令
- 找出裝置上目前的 network interface:
Network Interface Card(網路卡) 一端是連接通訊介質(乙太網、Wifi等),另一端則是提供主機的網路操作介面(network interface)
| |
2. 觀察某 network interface 流量
參考此篇文章 18 commands to monitor network bandwidth on Linux server,挑選了兩個不錯的工具 speedometer 用長條圖即時表現封包流量、tcptrack 觀察 tcp 連線狀態,方便後續實驗量測
3. 找出 domain name 對應的 ip
因為 tc 是網路層工具,所以要篩選封包需要透過 ip ,透過 $host {domain} 找出 ip。
tc 基本介紹
tc 的流量控制主要由四個概念組成
- Shaping :控制封包的傳輸速度
- Scheduling:控制封包的發送順序
- Policing:收到封包後的處理機制
- Dropping:流量超過帶寬後的丟封包機制
實作上有三個物件
- Qdisc (queueing discipline):
當 kernel 想要透過 network interface 發送 package 時,會先全部被放在 queue 上面,預設是 pfifo,不做任何處理單純的 First-In First-Out。 - Class
有些 qdisc 可以定義 Class,Class 主要用於做流量的管制,支援 Class 的 Qdisc 又稱為classful qdisc,每個 Class 又包含自己內部的 Queue,所以能組成層狀的網路流量控制 - Filter
決定 package 要送往哪個 class,每個 filter 是綁定在 qdisc 上。
幾種 Qdisc 介紹
qdisc 有非常多種,這裏挑幾個簡單介紹,屆時可依照屬性選擇使用
classless qdisc
- pfifo / bfifo
針對 Packet / Byte Buffer 容量限制的 First-In First-Out Queue,這種 queue 並不會對封包有額外的操作,收到就依照順序轉發,超過 Buffer 就丟掉,這是最簡單的 qdisc。
使用上如sudo tc qdisc add dev enp0s5 root pfifo limit 1000 - pfifo_fast
預設的 qdisc,內建是三條 pfifo(稱為 band),會依據 IPV4 header 中的 ToS 轉發到對應的 band,如果 band 中有封包,會從低順位的 band 開始發送,直到清空後依序換高順位的 band
classful qdisc
- tbf
也就是 Token Bucket 實作,主要用於流量整流增加平均流速 0.5mbps 高峰 1mbps+Buffer空間 5kbtc qdisc add dev eth0 handle 10: root tbf rate 0.5mbit burst 5kb peakrate 1mbit - prio
非常類似於 pfifo_fast,同樣預設有三條 band,但優點是可以自訂 priomap,決定 ToS 要對應到哪個 band (pfifo_fast 無法自定);
另外也支援 tc filter,用其他的條件決定封包轉發到哪個 band。 - htb
用於控制 outbound 帶寬流量,基於 Token Bucket 實作
* 補: working-conserving scheduler:
每種 qdisc 可分為 working-conserving 或是 non-working-conserving,working-conserving 表示不會讓資源 idle下來;
non-working-conserving 則是會在某些條件下延遲,可用於消遲抖動 (jittering )或是需要預期性的排程。
例如說 pfifo 收到封包後,就會立即送出;
對應的 tbf 就是 non-working-conserving,收到封包後,會看是否有 token 才會送出封包,並不一定是立即發生。
tc — 延遲封包
透過基本的 classless pfifo qdisc,實作:
- 透過封包延遲,放緩 http連線到 stackoverflow
- 透過 bandwidth(帶寬)限制,調整 aws s3 上傳的速度
以下指令參考
1. 列出目前所有的 network interface 的設定
| |
tc-prio 是預設的隊列規則,如果有綁定新的隊列規則會直接覆蓋過去。
預設 prio 會有三個 band,而 priomap 則表示對應 IP 封包中的 4bits TOS 欄位,將封包透過該 band 發送。
需注意 enp0s5 是我自己的 network interface,記得替換成自己裝置上的 network interface

http://linux-ip.net/articles/Traffic-Control-HOWTO/classless-qdiscs.html
2. 預設將所有的流量導向 band 2
為了避免其他封包被影響,先將所有的封包都走 band 2(指令計數從0開始)
| |
handle 1: 指的是綁定到 qdisc 的 root
bands 10: 可以創建 10組 band
3. 設定封包延遲
$ sudo tc qdisc add dev enp0s5 parent 1:1 handle 10: netem delay 100ms 10ms
- netem 是 tc 的工具之一,可用來增加延遲、掉封包、重複封包等模擬工具,
netem delay 100ms 10ms表示每個封包延遲 100ms(+- 10ms) - parent 1:1 表示在 class id 1 底下,建立一個 id 為 1的子節點,因為當前的隊列沒有多層次的 class設計,所以 1:1 就對應到 band 0
- handle 10: 表示創建一個 class id 為 10 的節點
雖然目前有增加了 band0 的延遲,但因為所有封包都是走 band2,還不會受到延遲的影響,先用工具量測目前的網路延遲,這邊我是用 curl
| |
在設定前不專業量測約為 1.5 s。
4. 加入過濾器,將符合條件的封包轉送到 band 0
$ sudo tc filter add dev enp0s5 protocol ip parent 1:0 prio 1 u32 match ip dst 151.101.0.0/16 match ip dport 443 0xffff flowid 1:1
- protocol 可以指定 ipv4 , ipv6 , tcp 或udp
- prio queue 的 filter 只能綁定在 1:0 底下,所以 parent 1:0 是固定的
- u32 是 tc 的工具,主要是針對 ip 內文做篩選,例如 match ip dst 表示對封包的目標位置坐篩選;
可以設置多個 match 條件 - flowid 1:1 表示此 filter 綁定到 band 0 上
- 多個 filter 可以綁定到同一個 band 上
設定完之後, 響應時間變成 12秒!
因為 netem 是針對 package 做 delay,一個 http(s) request 會來回多次,每次傳送不等多的 package,所以 每個 request delay 時間會遠比 1s 長。
使用 prio 非常方便的是,底下的 band 可以再另外掛其他的 qdisc,例如說加上 tbf 就可以限制帶寬,加上 netem 就可以流量整形,而且 band 數量可以自行定義,相當好用。
tc — 帶寬限制
剛才使用 pfifo qdisc,搭配 netem 做基本的流量控制,但如果需要控制帶寬,就需要用其他的 qdisc,配置 Token Bucket 或是 Leaky Bucket。
以下使用 classful qdisc HCB。

測試限制 aws s3 上傳的帶寬
1. 刪除舊的 qdisc 設定
| |
2. 建立 htb
| |
3. 加入 bandwidth 限制
| |
比對 s3 上傳的前後,發現上傳速度確實被限制在 100kbps
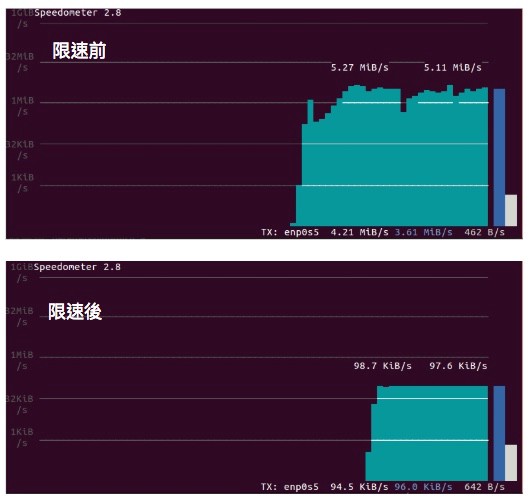
如果單純想要限制上傳速度,也可以用 tc-tbf,但 htb 優點是用層狀架構限速,leaf 會受到 root 的限制,例如分配一條帶寬 10 Mbps,可以在之下分配 4 Mbps 給某網域 6 Mbps 給其他網域等等。
筆記會用到的其他指令
- 使用 dd 創建指定大小的檔案
if: 檔案內容來源,/dev/zero是特殊檔案,讀取時會提供無限的空字元
of: 檔案內容輸出
bs: 每次寫入的區塊大小 (byte)
count: 總共寫多少個區塊$dd if=/dev/zero of=file.txt count=1048576 bs=1024
這樣會產出 file.txt 於當前目錄並佔 102MB - aws-cli 上傳檔案
$aws s3 cp file.txt s3://{bucket 名稱}
aws s3 在上傳檔案會用多個 thread 與 ip,所以要限制比較困難。
參考資料
網路相關參考自《计算机网络(第5版)》一書。