先前公司遇到 Client 在不明狀況下連續呼叫註冊用戶的 API 兩次,導致用戶被重複建立,導致後續的 API 操作與資料分析異常,所以決定加上 Lock 機制避免重複建立的問題
剛好在 Redis 官網看到 Redlock,一種 Redis 作者 antirez 基於 Redis 設計的分散式 lock 機制,並且已經有了 Nodejs 版本的實作,所以就決定採用這套方法,也確實解決了問題
本次部落格會摘錄官方說明 Distributed locks with Redis,並整理 Martin Kleppmann 提出質疑 How to do distributed locking與作者再次回復 Is Redlock safe?
題外話介紹 Martin Kleppmann,他就是《Designing Data-Intensive Applications》一書的作者,目前仍是我最推薦的工程書籍,可以參考之前的筆記
技術筆記 Designing Data-Intensive Applications 上
技術筆記 Designing Data-Intensive Applications 下
Redlock 簡介
當我們在設計分散式 Lock 機制時,有三點原則必須考量到
- Safety
當 Lock 被取走後,在釋放之前不能有另一個 Client 取得 Lock,也就是mutual exclusive - DeadLock Free
Lock 必須在一段時間後(TTL) 自動釋放,避免握住 Lock 的 Client 跨掉而 Lock 從此不能被釋放 - Fault Tolerance
整體系統不能有單一節點失敗的可能,必須考量系統容錯性
後續解說演算法實作時,會不斷去檢視這三點原則是否被滿足
需注意到容錯機制可能會聯想到 Master / Slave 架構,但是在 Redis 中 Slave 資料備份是非同步的,所以當 Master 掛掉到 Slave 接手,中間的時間差 Client 有機會取得多個相同 Lock,這會違反第一點原則,Cluster 架構同理
所以這裡作者提議的容錯機制主要基於 Multi-Master 機制,後續會有更深入的解釋
單機原則
再考量分散式設計之前,讓我們先思考單一台 Redis 如何實作 Lock 機制
取得 Lock
當要取得 Lock,可以用以下的指令
| |
NX 表示只有當 resource_name 不存在才創建這個 Key,避免重複建立,符合第一點原則Px 30000 表示 Key 的 TTL 是 30秒,符合第二點原則
釋放 Lock
| |
在釋放 Key 時,必須先檢查 Key 對應的 Value是不是我們一開始塞進去的值,也就是上個步驟的 my_random_value,這是要確保移除的 Lock 是當初我們取得的 Lock,試想一下情況
| |
步驟四如果沒有檢查,Client A 不小心移除了 Client B 的 Lock,此時就會破壞第一點原則
Random String
Random String 的產生機制,可以取 /dev/urandom 的 20 bytes,/dev/urandom 是*unix 系統產生偽亂數的方式,依據設定的不同可能是從環境噪音、網路數據封包等外在物理現象,這樣的做法可以保證較好的隨機性,也可以用其他簡單的方式,例如取系統時間加上 client_id 等等,取決於實作者的設計
套用至分散式系統
取得 Lock
假設目前有 N 台 Redis master,這 N 台都跑在獨立的環境上而非使用 Cluster 架構,假設 N=5,以下是實作步驟
- 取得當前時間 T1
- 用相同的 Key / Value 依序取得 N 台的 Lock,在取得 Lock 時要設定連線Timeout,此 Timeout(ex. 5~50ms) 應該遠小於 Lock 的 TTL (ex. 10s),避免 Client 浪費太多時間在等死掉的 Redis Server,Client 因儘速取得 Lock
- 當取得 Lock 後,假設此時時間為 T2,Client 檢查 T2-T1 是否大於 Lock 有效時間 TTL,只有當
時間有效且大多數的 Redis Servre(過半數,也就是 >=3)才算是有效取得 Lock - 此時 Lock 僅剩有效時間是 T2 - T1
- 如果 Client 取得 Lock 失敗 (例如有效時間是負數、無法取得過半 Redis Master Lock),Client 必須對每一台 Redis Master 發送釋放 Lock 指令,即使該台 Redis Master 沒有給他 Lock
分散式代表各個程序沒有同步的時間上,而且每台機器因為計時器的物理性質,會有時間偏差的問題(Clock Drift 問題)
時間計算會影響第三步驟的有效時間,所以需要減去一點偏差當作補償,但現實世界的時間計算頂多就幾個毫秒的誤差
所以實際 Lock 的有效時間會是 TTL - (T2-T1) - CLOCK_DRIFT
Retry
如果 Client 取得 Lock 失敗,應該在一定秒數後隨機 delay 一段時間,再次重新嘗試,隨機 delay 是為了錯開同時多個 Client,讓較快者可以先取得 Lock,如果 Client 沒有取得 Lock,應該儘速釋放 Lock
釋放 Lock
同時向所有的 Redis Master 釋放 Lock
檢驗演算法
因為再依序取得 Lock 會有時間差,假設 Client 從第一個 Redis Master 取得 Lock 時間為 T1,最後一個 Master 回傳時間為 T2,那麼第一個 Lock 僅剩的生命時間是 TTL - (T2 - T1) - Clock Drift,這也就是最小有效時間 MIN_VALIDITY;Clock Drift 是上述的時間誤差;(T2-T1) 則是取 Lock 的等待時間
假設 Client 取 Lock 時間 (T2-T1) > TTL,也就是 Client 取到最後一個 Lock 時第一個 Lock 已經失效了,那此時就會全部釋放,不會有錯誤產生
假設 Client 成功取得 Lock,那在先前的條件保證,沒有其他用戶可以在 MIN_VALIDITY 內取得大多數 Master 的 Lock,也就不會破壞 Lock 的原則性
要確保 MIN_VALIDITY 的時間內關鍵資源能夠運作完成,不然 TTL 過後 Lock 被其他人取走,Lock 就失去互斥原則
性能、故障復原
Redis 常用於高性能需求的場景,我們會希望 Lock 取得/釋放可以越快,增加 throughput 與降低延遲,在過程最好的方式是 Client 同時向多台 Master 取 Lock
另外考量到故障復原的部分,假設今天取得 Lock 後 Master 故障了,假使沒有開 AOF 儲存機制,那可能 Lock 沒有保存到磁碟上,復原時遺失就有機會違反第一點原則
假使有開 AOF,也記得要調整 fsync 頻率,最保險是設成 always,但這會影響性能
但除了即時資料備份到磁碟上外,還可以考慮另一種做法,當 Master 故障復原後,延遲重啟的時間大於 TTL,也就是說讓原先 Master 上的 Lock 都釋放或自動失效,之後再重新加入就能避免違反安全原則,不過要小心如果超過多數的 Server 故障,需要等相對長的時間才能重新運作,此階段 Lock 都無法取得
最後如果有餘裕可以設計延長 Lock,讓握有 Lock 的 Client 可以延長手中的 Lock
以上是摘錄自官網文件的整理
Nodejs Package - Redlock 實作
看完演算法,來看一下 Nodejs 版本的實作 mike-marcacci/node-redlock
他在 Redlock.prototype._lock 部分實現 Lock 機制
截幾個關鍵片段,輪詢所有的 server
| |
request 主要封裝 lock 的 script,支援如果同時多個 resource 要鎖可以一起鎖
| |
這一段考量到 drift 問題,檢查 Lock 的有效時間,並且只有在取得多數 Redis Server 同意才往下繼續
| |
主要關鍵是這幾個部分,其餘的就是封裝
Martin Kleppmann 的質疑
中斷導致 Lock 有效判斷錯誤
在分散式系統設計中,時間是一個非常難以掌握的因素,程序可能因為各種狀況而導致時間序錯亂,例如說系統時間不準、網路延遲、程式運作遇到垃圾回收、作業系統切換 Process 導致中斷等,所以各種檢查機制都有可能因而出現錯誤,例如以下的例子
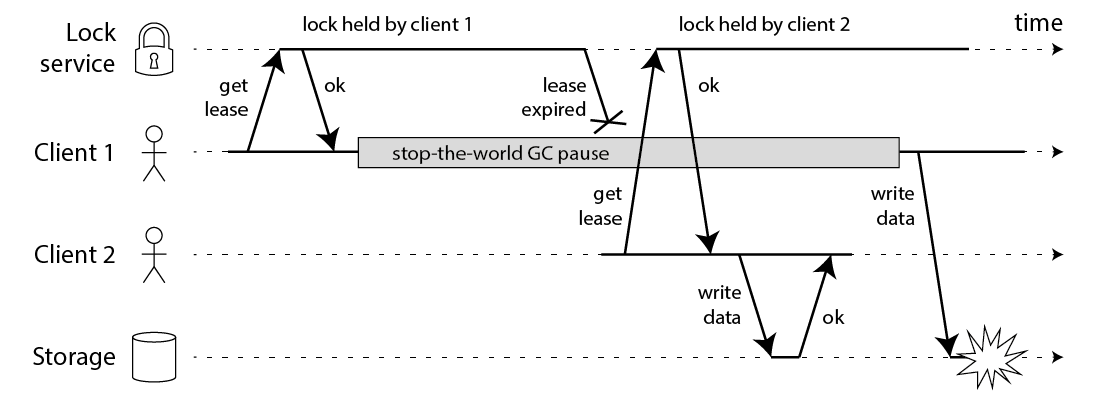
- Client1 取得 Lock 後
- 結果遇到 GC 暫停運作
- Lock 超過 TTL 自動釋放,此時
- Client2 成功取得 Lock,並更新 DB 紀錄
- 接著 Client 從 GC 中恢復,他以為自己手上有 Lock 可以去更新 DB
這樣就違反了 Lock 的安全性原則
直覺解法是在更新 DB 之前 Client 再去檢查 Lock 的時效性,但 GC 可能卡在檢查完之後的那一個點,所以設定再多檢查都是沒用的
實際解法也蠻直覺的,系統全域有個不斷遞增的發號機制,每取一次 Lock 就配一個數字,在 DB 更新的時候,檢查對應的數字是不是有大於上次更新的數字,就可以避免掉上述提到的問題,就是 Fencing 機制

太快樂觀預估時間的複雜性
TTL 的「時間」計算有實作問題,Redis 目前使用 gettimeofday 而非 monotonic clock 的時間
前者是系統時間,這是可以被調動,例如 NTP Server 同步 / Admin 手動調整等,所以時間可能大幅度前後跳動
而後者是每當 timmer 發出 interrupt 就 持續遞增永不回頭,所以在判斷兩個點的絕對時間差用後者會比較精準
試想如果 Client1 取得 Lock 後 Redis 時間跳轉立刻 Lock 失效,結果 Client2 又可以拿到 Lock,就會違反安全性原則
此外 Martin Kleppmann 認為 Redlock 預設太多時間因素是可預期的,像是網路延遲、時鐘偏移等問題,但這不是分散式演算法正確的設計方式,所以 Redlock 的安全性是建立在半同步系統當中(意即各種時間因素是有上限且可以被假設的),而不是真正的分散式設計
antirez 再次回復
以上兩點主要是被質疑的部分,接著看 antirez 回覆
當自動釋放機制導致 Lock 的 Mutual Exlusive 機制失效時
在 Martin 第一點質疑中,他覺得要加上遞增的 Token 當作保護機制,避免 Client 手上 Token 過期還去更新 Resource,達到強保證性
讓我們先回過頭來想為什麼我們會需要分散式 Lock,正是因為我們的關鍵資源本身沒辦法一次只服務一個請求 (linearizable),如我自身案例是 API Server 同時有多台
而 Martin 提出的系統全域有個遞增 Token,關鍵資源在操作時會先去檢查 Token,這本身就是個 linearizable store,讓所以的操作不再併發而變成線性逐一處理,這本身就與分散式的現況矛盾
再者如果有個遞增 Token 系統,那 Redlock 在產生 Lock 的 Value 時,用這個遞增 Token 取代原本的隨機字串也有一樣的效果
又或是根本不需要遞增函數,只要把隨機字串也記錄到關鍵資源上,在操作時去比對先後兩者是否相同,同樣有 Fencing 的效果
基於時間的過多理想化假設
作者承認 Redis 應該改用 monotonic time,但是看來還沒有個結論是否要修正 Redis Repo - (#416) Use monotonic clock when available,主要問題在於並非所有系統都支援 monotonic time API
關於時間跳動的問題,作者並沒有給出很明確的答案,但看來只能盡量避免(例如 Admin 不要改動系統時間)而不是從演算法的部分改進,因為目前 Redis 還不是用 monotonic time API
接著考量一個情況
- 取得當前時間
- 取得 Lock
- 計算當前時間
- 檢查 Lock 是否還在有效期間
- 如果有 Lock,則繼續處理
在步驟一到三,不論是網路延遲、程序中斷等時間問題,都沒有關係,因為步驟四會再次檢查 Lock
但如果是在第四步到第五步之間,這時候沒有任何有自動釋放機制的分散式 Lock 可以保證 Mutual Exclusive,只能靠關鍵資源本身的機制,這就回到上一步說的 Fencing 機制,例如說 DB 就寫入遞增 Token 或隨機字串,讓後者不能更新
所以 Redlock 安全嗎?
答案取決於對於安全的要求有多高,
- 配置多台 Redis Server 並開啟 fsync = always 的 Redlock 機制
- 在系統時間沒有大幅度跳動的情況下
- Lock TTL 保證大於關鍵資源的運行時間或是在關鍵資源處有 fencing 機制
符合這三點 Redlock 就是安全的
正因為我們沒有其他方法避免 Race Condition,才會採用 Redlock 或是其他樂觀鎖的處理機制