最近有一些自建搜尋引擎的需要,所以找上了 Elasticsearch 這一套開源的分散式的 NoSQL Database,這一篇文章主要分享自己如何評估 Elasticsearch,著重在系統的架構與內部實作機制,教學預計會拉到另外一篇文章
以下內容大多參考此本書:《Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine》,雖然是 2015 的書,但內容相當的豐富,還有豐富的內部實作機制/Cluster架構等等的補充,除了 api 有些參數要更新外,不會因為時間而抹滅他的價值,包含了有趣的浪漫故事
Elasticsearch 原作者其實是為了幫老婆寫一個食譜搜尋引擎而開始的,但過了好幾年 Elasticsearch 都變成公司了但老婆依然還沒拿到說好的食譜搜尋引擎…. (截至 2015年)

Terminology 與基礎介紹
Elasticsearch 是建構在 Lucene 這個 Java 開發的搜尋引擎上,增加了分散式與 API 呼叫的介面;
資料層級分成 Index > Document,每個 Index 當第一筆 Document 建立後會有隱式的欄位型別,後續的 Document 都要遵守型別,其中 Index 這個詞蠻容易誤會,因為他除了代表最上層的資料集合外,也代表索引的同義詞
Elasticsearch 儲存時是用 JSON 格式,可以對每個欄位設定型別,同時可以指定是否支援全文搜尋
為了支援全文搜尋,Elasticsearch 使用 Reverted index,也就是用一張表紀錄一個詞在哪些 Document 中的欄位出現過
Warning: 在 6.x.x 版時 Elasticsearch 移除了 Type 層級,主要是因為當一個 Index 下有多個 Type,假設多個 Type 有相同名稱的欄位,對於 Lucence 來說會把兩個相同名稱欄位都當作同一個,所以如果想要兩個不同 Type 中相同名稱欄位設定不同型別是會拋出錯誤的 (ex. Index 下有 User / Twitter 兩個 Type,且兩個 Type 都有 user_name,則 user_name 必須是相同型別),所以經過考量後就移除了
參考文件 Removal of mapping types
在建立索引時,Elasticsearch 會將欄位經過 Analyzer 處理,也就是 charaterizer -> tokenizer -> token filter
所以能夠支援像過濾介系詞 / 將文字轉成小寫或是同義詞轉換 / 支援不同語言的斷詞等靈活的語言處理流程,所以才能夠提供別於一般資料庫死板的全文搜尋
在資料更新與查詢時,Elasticsearch 提供近乎即時的操作,同時查詢支援依照條件篩選 (Filter) 或是依據關聯度排序 (Query)
前者像是 給我 id 是 123 的資料這類 yes/no 問題;後者是回答 幫我找出跟 Mary 相關的文檔 這類模糊搜尋的結果
架構介紹
Elasticsearch 支援分散式,可以在 Index 層級指定要 Sharding 配置方式,Shard 有兩種角色 Primary / Replica,前者負責讀寫而後者負責從 Primary 備份資料並分散讀的查詢,每一個 Shard 執行獨立的 Lucene,可視為獨立的 Worker
即使在單機上跑,Elasticsearch 也會按照配置,將資料拆分儲存
如果 Cluster 此時增加機器,Elasticsearch 會自動將 Shard 分散到各個節點上,如果有 Replica 則盡可能分散風險讓每台機器都有備援資料
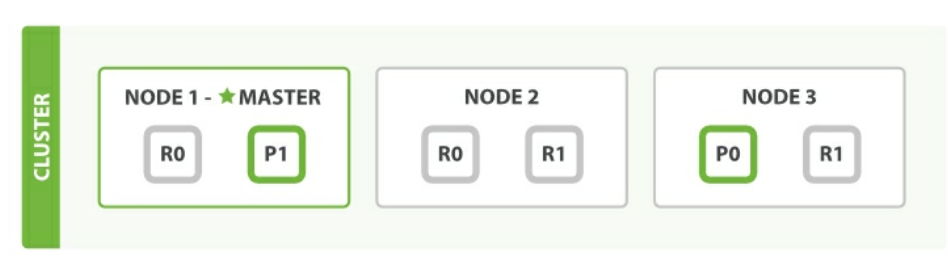
Cluster 之間會有一個 Master,Master 主要管理整個 Cluster / 加入、移除節點 / 建立 Index 等,例如查詢/寫入都是個節點能夠獨立完成,所以不需要擔心 Master 會成為系統的 Single Point of Failure
節點發生問題,Cluster 會自動票選 Master 並重新做資料搬移的動作
實際上 Node 有分很多類型,像是 Master Node 負責管理 Cluster / Data Node 儲存資料 / Ingest Node 預處理流程等等
服務評估
主要是針對各種維運上的點進行考量,看到 分散式資料庫都會有三個特點
**Replica**: 資料如何備援**Sharding**: 如何拆分資料集**Cluster**: 如何水平擴展機器
一般來說分散式資料庫的 Replica 都是由 active slave 擔任,即時備份所有的更新,同時能夠支援讀取的分擔,各家提供的功能都差不多;
至於 Cluster / Sharding 則各家資料庫的實作與考量各有不同,同時考量到 CAP 在可用性與資料一致性之間做取捨這是我覺得最有趣的地方
實際評估上會去思考以下幾個案例,同時以我比較熟悉的 MongoDB / Redis 作為對比
- 基礎資料庫
a. 寫資料時如何保證 Durability
b. Concurrency 下的 Consistency 保證是什麼 - Sharding
a. Sharding 的依據是什麼 / 是否能夠動態增減 shard
b. Query 如何 routing 到正確的 shard 上面 - Cluster
a. Cluster 基本架構要如何搭建
b. Cluster 調整時需要做什麼改動
c. Cluster 增減 node 時會有什麼變化
d. Cluster 在什麼情況下會不可用
基礎資料庫
寫資料時如何保證 Durability
Elasticsearch 為了平衡 Durability 與效能,所以當 Reverted Index 建立後就是 不可變 immutable的,這樣的好處是性能帶來很大的提升,資料載入 memory 後不用擔心會變動 / mulit thread 也不用擔心資料過期的問題等等
但資料不可避免會遇到更新或刪除的需求,所以 Elasticsearch 採用 Segment 方式,每次建立 Index 後就是一個獨立的 Segment,累積一批修改後在建立一個新的 Segment
查詢資料時就同時查找多個 Segment,如果同筆資料在多個 Segment 都有紀錄,則採取最新一筆的資料
實際的Elasticsearch 內部儲存機制的方式參考下圖
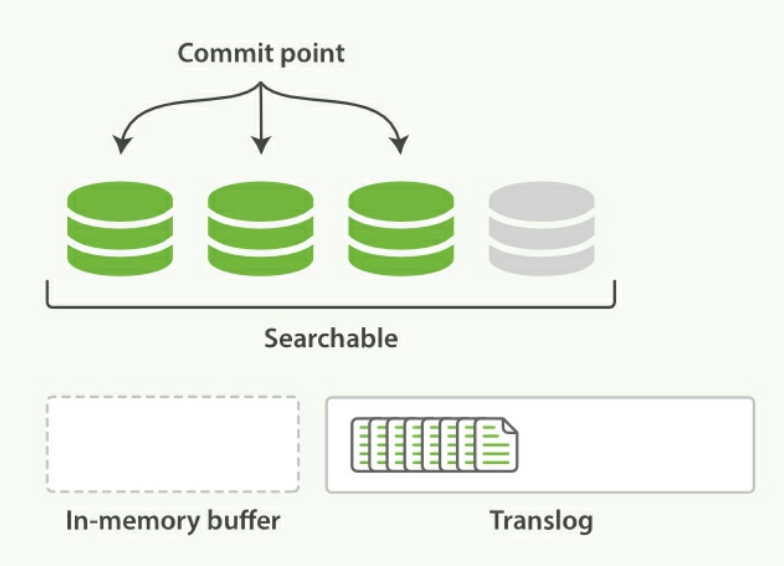
儲存機制如下
- 新的修改產生,寫進 in-memory buffer 中,此時資料不能被搜尋
[Refresh]固定時間 refresh 到 file cache (灰色的 Segment,代表還沒真正儲存到硬碟上),此時資料可以被搜尋 (預設每 10秒)[Flush]固定時間 file cache 透過fsync寫入硬碟,此時才是真正的持久化 (預設每 30分鐘或是 Translog過大時)- 每次 Flush 會產生新的 Segment,但如果 Segment 太多會造成檔案過多性能反而下降,會固定時間合併多個 Segment
但要小心 Segment 合併會吃掉大量的記憶體與 CPU,所以也不能夠太頻繁,可以指定max_num_segments參數 - Translog 是為了確保 2~3 步驟如果機器發生問題,可以透過 Translog 回復資料
Translog 將每筆操作順序寫入硬碟,當第三步 flush 後一併清空
但 Translog 本身也有 fsync 的頻率,預設是 5 秒鐘,所以有機會丟失 5秒鐘內的資料
Redis 在持久化保存有分 RDB 與 AOF,RDB 是透過保存整份 Snapshot / AOF 則是寫入每筆操作 log 預設每秒 fsync 到硬碟上
Concurrency 下的 Consistency 保證是什麼
對 Elasticsearch 進行寫入操作時,針對 Request Level 可以做不同的保證性,預設是 sync,也就是 Primary + Replica 都寫入成功才返回,資料不用擔心會不見;
可以調整成 async,只要 Primary 寫入成功就返回,但可能資料會不見;
但書中提到建議還是用 sync,因為如果 Elasticsearch 此時負載較高,可以讓 Request 較晚回覆產生 back preasure,否則可能會讓系統乘載過多的 Query
在併發的狀況下,Elasticsearch 採用樂觀鎖,透過_version去比對更動是否為正確的版本,預設的_version 是遞增的數字,也可以用自定義的 _version
Sharding
Sharding 的依據是什麼 / 是否能夠動態增減 shard
Elasticsearch 在建立 Index 時,可以指定 sharding 的數量,設定後如果要更動,就必須要先關閉 Index 寫入並調整設定
至於資料如何分配到 shard,則是由內部的 hash function 對 id 做運算,Elasticsearch 會自動 balance 資料
MongoDB 則是需要對 collection 指定 shard key,可以分成 range shard / hash shard,前者可自己指定 shard 要儲存的 key 範圍,後者同樣有內部 hash function 決定,MongoDB 會自行負責 balance;
Redis cluster 預設有 16384 個坑,透過 hash 運算(CRC16 mod 16384)分散 key 到現有的 Node 上面,如果動態增減 cluster Redis 會自行處理資料搬移
Query 如何 routing 到正確的 shard 上面
Elasticsearch 每一個 Node 都能夠處理 Query,會在內部自己 routing 到資料所在的 Node 上,另外為了效能,如果是讀取且有 replica,Elasticsearch 會用 Round-Robin 去分散讀取的壓力
MongoDB 則需要 Mongos 去處理 query,所以多一個服務要架設,也造成服務多一個中斷的可能;
Redis Cluster 也是每一個 Node 都能處理 Query
Cluster
Cluster 基本架構要如何搭建
Elasticsearch 在 Cluster 架構上非常彈性,要幾個 Node 都可以,同時可以針對不同的 Indices 去調整 sharding / replica 數量,Elasticsearch 會以容錯度最高的方式自動分配
但建議還是 Cluster 還是 3 台以上,才可以讓可用性更高
如果只有兩台,發生 Network partitioning,假設要保證 Consistency 要過多數的小 Cluster 能夠運作(避免 split brain),則兩邊各一台就會服務中斷,在 Network partitioning 下沒有任何的容錯性
所以 Cluster 基本都 3台起跳且選擇奇數
MongoDB Cluster 只少要 3 個 Node (至少兩個可儲存的 Node),如果是 Sharding Cluster 則需要 Config Server (3台) + Replica set (3台起跳) * n,外加 Mongos
Redis Cluster 則也沒有限制,要加幾個 Node 都可以,如果要備援則設定 slave node
Cluster 調整時需要做什麼改動
Elasticsearch 再增加新的 Cluster Node 時不需要額外的設定,只要確保 Network 可以 multicast 且設定同一個 cluster name,就會自己加進去
MongoDB 需要改 Config Server 設定檔 / Redis Cluster 也是
Cluster 增減 node 時會有什麼變化
Elasticsearch 再設定檔,可以指定 Primary 與 Replica 的數量,並平均分散到每一個 Node 上
例如說 Primary 2 + replica 1,則會產生 P1 / P2 + R1 / R2,假設目前有兩個 Node 他會自動分配成 P1 + R2 / P2 + R1 分散風險,掛了一台資料也不會掉
MongoDB 的 Cluster Node 主要有兩種 secondary / 僅投票用的 Arbiter (撇除 Primary)
Redis Cluster 沒有特別區分 Node 性質
Cluster 在什麼情況下會不可用
Elasticsearch / MongoDB / Redis Cluster 這方面都是類似的,當發生 partitioning 時,只有超過半數的 cluster 可以運作