Gossip Protocol
Gossip Protocol 是一種通訊機制,應用於同一網路內機器與機器間交換訊息使用,原理類似於辦公室傳謠言一樣,一個傳一個,最終每一個機器都擁有相同的資訊,又稱 Epidemic Protocol
上一篇分享到 Cassandra 內部如何使用 Gossip Protocol,影片中有推薦 Efficient Reconciliation and Flow Control for Anti-Entropy Protocols,以下摘要此篇論文所探討的內容
建議可以先讀上篇,有個概略認識後在看理論會比較好懂些
《Efficient Reconciliation and Flow Control for Anti-Entropy Protocols》 摘要
anti-entropy,又或稱作 gossip,用於不需要強一致性的狀態同步,在一些限制下,時間複雜度是 log(N) (N 為群體數量) 且在 host 遭遇錯誤或是訊息丟失都不影響
gossip 希望盡量在可控制的回合內完成同步,但如同其他同步操作,這會仰賴 CPU 資源與 Network 流量,在高負載下 CPU 可能來不及運算要更新的狀態或是網路流量不夠快導致延遲封包
這份論文主要提供兩個價值,
- 在限定 CPU / Network 下優化 gossip protocol 傳輸效率
- 分析 gossip protocol 的流量管制
gossip protocol 主要有兩種類型
- anti-entropy: 持續傳送 gossip information 直到全部資料都更新完成
- rumormongering: 選定一個足夠有效的時間持續送 gossip information,大概率節點都會拿到最新資訊
假設目前的集群 {p,q …},每個參與者都需要維護一份列表,這個列表是由 key -> (value + version) 組成,也就是 Cassandra 內的 ApplicationState
σ ∈ S = K → (V × N ) // σ 代表取狀態 σ(k) = (v, n) ,表示 key 此時對應的 value v 跟 version n
列表包含 key -> value -> version,如果是這個 key 的最新資料,則他的 version 會大於舊的 version
σ1(k) = (v1, n1), σ2(k) = (v2, n2) // σ1(k) 代表這一個節點取他的 key,返回 (v1, n1) 代表 value 為 v1 且 version n1; σ(k) 表示取 σ1 與 σ2 取 XOR,並遇到相同 key 時取 verson 較大者,也就是如果 n1 > n2 則 σ(k) = (v1, n1)
操作流程大致是
- 從集群中隨機挑一個 host 傳送訊息,訊息內容是自己所維護的列表
- 收到訊息後運算,此動作稱為 merge 或稱為 reconciliation ,也就是收到訊息時會去運算列表的差異,並保留差異中 version 較高的 key -> value
∀r : µq (r) = µq (r) ⊕ µp(r) // q 真正要更新的是 p 傳來的訊息與 q 自身現在的訊息取 XOR 找出差異處
傳送訊息有三種格式
- push: 節點 p 傳送整份列表,節點 q 收到則計算 merge 後合併入自己的列表
- pull: 節點 p 傳送 key -> version 而沒有 value,節點 q 回傳節點 p 須要更新的鍵值,變免多餘的值傳送
- push-pull: 就像 push,節點 p 傳送完整列表,節點 q 會回傳 p 過期須要更新的鍵值 ( pull 後半段,
push-pull 是最有效率的做法
如果某個 key 不再更新,那在一定的時間內很高的機率大家都會同步相同的 value,如果集群隨機挑選節點的演算法 (Fp ⊆ P − {p}) 夠隨機的話,即使遇到 message loss 或是 host 短暫 failed,也僅僅是稍微延遲同步的時間
假設 update key 的時間是固定的,那隨著集群數量線性增長 N,則達成同步所需要的時間會成 log(N) 增長。
但實務上必須考量到 CPU / Network 以及更新的頻率,如果更新的頻率太高,因為資源受限則同步的延遲可能會無限的增長,實際上應用程式在意的不是多常更新,而是資料是不是抵達同步
接著要探討如果我們限定 gossip message 不能超過 MTU(Maximum Transmission Unit),那我們該怎麼決定要更新哪些 key 才能最有效讓所有節點狀態一致
RECONCILIATION
先前提到 p 跟 q 來回通信都只送兩者狀態的 delta,如果超過 MTU 則必須有一個優先序決定哪些鍵值要先更新( <π 代表此排序演算法),作者介紹了兩種,一種是 precise reconciliation 最為基準線,對比另一個作者提出的 Scuttlebutt 更新機制
precise reconciliation
根據更新時間序決定哪些 key 要先送出去,在實務上 precise reconciliation 比較麻煩些,如先前說必須要先送 state 給對方做比較才能算出 delta,這會消耗頻寬以及 CPU cycle
依據時間序又可以細分成 precise-oldest: 在 MTU 限制下先送那些很久沒有更新的 key / precise-newest: 先送最近才被更新的 key,後者要留意會有 starvation 問題,在實作上節點必須同步時間,才能作為判斷的依據
Note that, if implemented, both these orderings would require a synchronized clock among the members and that all updates be timestamped with this clock.
Scuttlebutt Reconciliation
作者提及另一種解法,也是 Cassandra 採納的做法,初始化時 version 固定是最小的數字,每次更新鍵值時,要把 version 設定大於成目前任意鍵值對應的最高版號
{(r, max(µp(r))) | r ∈ P}// 此公式表示 r 是屬於節點 P 的屬性,找出 r 以及當下 P 中 r 最大的版號;
例如說目前 Participant p 的列表是
| |
如果此時 a 要更新,則版號至少要拉到 4,而且不像 precise-conciliation 會一次送多組間值更新,Scuttlebutt 允許一次可以送一個鍵值,但必須按照 version 大小逐一送
整個架構必須符合以下狀態
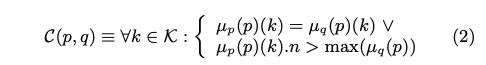
也就是說在整個集群下,任一鍵值 k 在節點 p / 節點 q 必須滿足以下任一條件
- 在節點 p 跟節點 q 中同一個 key version 是一樣,代表
資料已經同步 - 如果節點 p 的 key version 跟節點 q 不同,則此 version 必須比是節點q 中任意最大的版號還要大
第二點非常重要,這是保持每次更新不需要整包送,先從版本判斷就能判斷哪些欄位真的需要更新的依據
來看一個實際案例,目前有三個節點 r,p,q,共有 3 個 key a,b,c,可以看到 t1 時 r 的三個 key 都被更新過,版號分別是 21/22/23;
此時 r 要向 p,q 發送 gossip message,他必須先從 a 開始,因為這是 a,b,c 三者中版號最小,且大於 µq(p) / µp(p) ,這意味著節點 p 和 節點q 都要更新,所以 r 會同時送訊息給 p , q,在 t2 時只有 key a 先被更新

可以回去看 Gossip 介紹(上)的 GossipDigestSynMessage 部分
雖然說一次只更新一個鍵值效率好像很低,但優點是 r 不需要送已經更新過的值,減少重複,在頻寬有限情況下,Scuttlebutt 也必須決定 gossip message 傳送的優先序,這裡有兩種做法
scuttle-breadth: 在同一個 participant 中,將 delta 用 version 從小到大排序,如果兩個不同 delta 的 version 相同,則隨機抽 participant 發送scuttle-depth: 在 participant 中,只有鍵值有落差就算一個 delta,從 delta 最多的 participant 開始送,所以有可能都送給同一個 participant
實驗結果
總共 128 participants 與 64 組 key/ value,每秒每個 participant gossip 一次;
前 15 sec 暖機,並開始限縮頻寬 / 25 秒開始加倍更新頻率 / 75 秒更新頻率回歸正常 / 120 sec 停止更新,中間 25~75 加大流量主要是想要看演算法在高負載下的表現,以及高峰過去後的恢復速度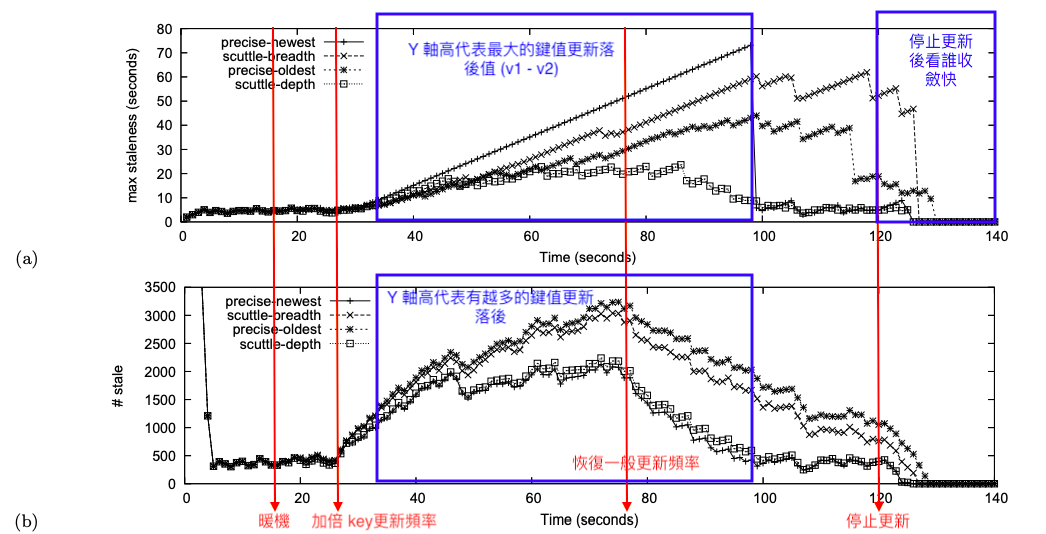
- 第一張圖表代表這一個時間上,該鍵值自從上次被更新後隔了多久才收到最新資訊,越低者越好
staleness of such a mapping µq (p)(k) is the amount of time that has lapsed since µq(p)(k) was last updated
- 第二張圖表代表這一個時間有多少個鍵值是過期的 ,越低者越好
reports the number of stale mappings as a function of time
交叉比對有以下結論
Scuttle-depth 表現優異- Precise-newest 可以看出有 starvation 狀況,也就是有鍵值很久沒有被更新 (圖一他最高),但是真正影響到的鍵值其實是少數 (同一時間點其實過期的鍵值數不多),但是高峰過去收斂很快
- 其餘兩者表現普普
Flow Control
在一些情況下,participant 交換訊息時更新頻率可能不同,所以會需要一個流量控制的演算法,去平衡一個 participant 想要增加更新頻率而另一個想要降低頻率的可能,要製造出這樣的不同更新頻率,但同時系統必須維持相同的最大交換頻率上限
在 participant 交換 gossip 時,會連帶交換彼此預設更新的頻率 (ρp , ρq)以及最大值 (τp,τq ),當兩個 participant 在交換時會順便交換
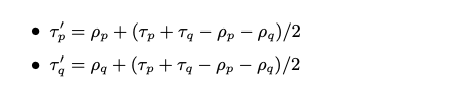
機制有點類似於 TCP 的 Additive Increase Multiplicative Decrease (AIMD),逐漸增加發送的頻率但遇到錯誤時快速減少;
如果要發送的 delta 數量高於 MTU,則線性增加,反之,則倍數減少
實驗過程是在 t = 90 時限縮 mtu 從 100 降到 50,可以看到 90 之後 max out of date 大幅增加,之後才慢慢收斂,其中 scuttle-depth 在表現上比較穩定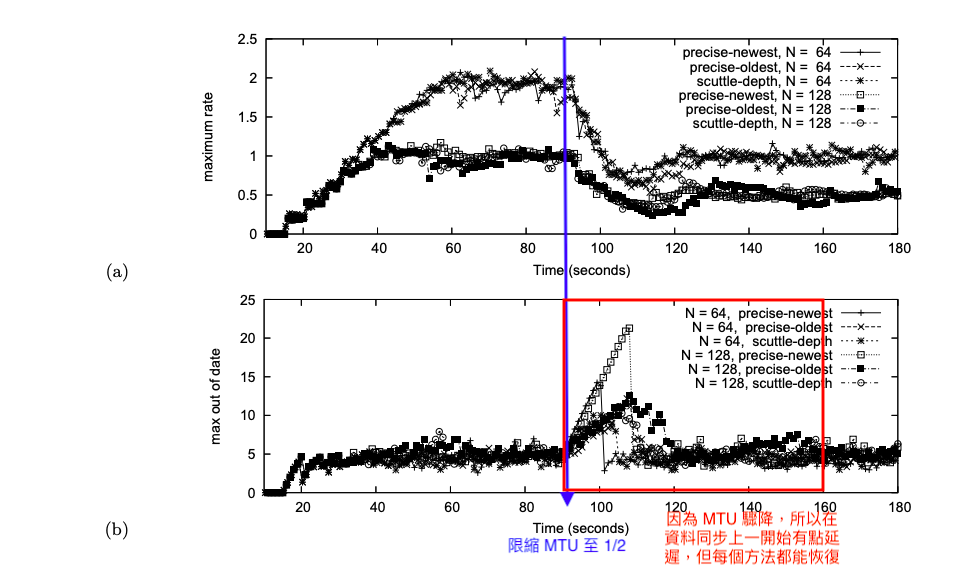
這一章節比較不確定,如果有什麼錯誤麻煩指教 🙏
總結
本篇提出兩個重點
- 新的 reconciliation 機制,加速同步的效率,同時避免 starvation
- 引入 flow control 機制,讓 participant 可以用合理的速度更新
實作面
網路上找了一個 nodejs 版本的 gossip protocol 實作 node-gossip,看起來是使用 scuttle-depth 協議機制 計算與 peer 中的 delta 最多的,接著先按照 peer 中最舊的 version 開始排序
| |