共識演算法主要應用於分散式系統中,一個集群中有多個節點組成,讓每個節點都維護相同的狀態,例如說在多種系統中都需要集群有單一個 Leader 存在,所有節點都必須承認這一個 Leader,否則多個 Leader 可能會導致 Split brain 等資料不一致等問題;
但如何讓節點狀態一致是一件不簡單的事情,要考慮到節點可能失敗 / 網路封包延遲等等
Raft 演算法是由史丹佛大學的教授所提出,他在影片中提到過往的共識演算法 Paxos 過於複雜,世界上真正了解的人沒有幾個,市面上的實作也分歧出非常多的實作版本,理論太過艱深導致實務上有很大的落差
所以他在設計 Raft 的一個核心理念是好懂,他在 Conference 上也僅用約 10 分鐘就大致介紹完 Raft 的原理,整份論文也才 16 頁
以下將整理影片介紹與論文摘要,探討 Raft 如何在分散式系統中讓多節點在容忍錯誤下達到強一致性
影片介紹
先從在 Conf 上的介紹影片快速理解,Raft 由三個部分組成
Leader Election:
整個集群中票選出一位 LeaderLog Replication:
Leader 負責接收 Client 的指令,並把狀態同步到多數節點上Safety:
當 Leader 要重新票選時,確保擁有最新資料的節點才能當上 Leader,避免確認過(commited)的資料被取消
以下將摘要論文 《In Search of an Understandable Consensus Algorithm (Extended Version)》部分內容
論文摘要
Raft 是一種用於管理副本紀錄的共識演算法,效果類似於 Paxos,但結構上完全不同,這也使得 Raft 相較於 Paxos 更容易了解
為了增加可讀性,Raft 解構出幾個共識演算法中關鍵的元素,像是 Leader Election / Log replication / Safety,並透過減少狀態達到更強的凝聚性 (意指節點可以變化的狀態少,就更容易達到一致)
1. Introduction
共識演算法 (Consensus) 提供由機器組成的集合可以運作類似同一體並能夠容忍部分成員出錯,也這是這些特性,共識演算法在建構大型軟體系統是很關鍵的角色
Paxos 主宰這一塊近十年,但不幸的是 Paxos 很難懂,同時在實務上需要有很負責的設計才能夠使用,所以不論是學生還是系統工程師都十分困擾
所以作者開始想要設計一門足夠好理解、同時對於系統工程師也容易實踐的共識演算法
our primary goal was
understandability: could we define a consensus algorithm for practical systems and describe it in a way that is significantly easier to learn than Paxos
透過解構出獨件以及減少機器在不一致狀態的可能性,讓整個演算法更容易理解
Raft 有以下幾個特點
- Strong Leader:
Log 的寫入必須經由 Leader 再到其他節點上,這樣可以簡化很多不必要的複雜性 - Leader Election:
在選舉時,Raft 利用隨機延遲(randomized timers)方式快速且有效解決可能的衝突 (避免大家在同一個時刻想要變成 Leader) - 身份改變
在改變節點的設定檔時,可以將前後兩種設定檔以聯集方式合併(joint consensus),在更改設定同時還能維持服務
作者認為 Raft 是個優異的共識演算法,就讓我們繼續往下看
2. Replicated state machines
Replicated state machines 是指一群機器的集合,可以運算出相同的狀態,並在少數節點失敗時還能正常運行,主要用來解決分散式系統中各種錯誤容忍性的問題,例如 GFS / HDFS / RAMCloud,在這些系統中有獨立的 Replicated state machine 掌管 Leader Election / 保存 Config,在 Leader crash 情況下還能繼續運作; Replicated state machine 的實際案例有 Chubby / ZooKeeper
Replicated state machine 通常是由複製 Log 所實踐,如下圖,每個 Server 都有一份 log,依照相同順序紀錄著相同的指令,運算整份 log 就能得到相同的狀態機 (state machine)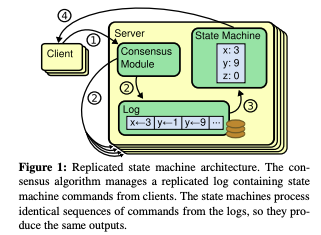
從 client 收到指令後,如何保持順序複製相同的指令到每台機器上,就是共識演算法的任務,共識演算法具體提供下列保證
- Safety:
在非拜占庭情況下,系統即使遭遇網路延遲、網路分隔 (partition)、封包遺失、指令重複發送、發送順序改變等問題,都不影響結果 - 只要多數節點存活就能夠正常運行,例如 5 個節點 3 個還活著就可以,並且失敗的節點可以在後面重新加回集群中
- 不依賴時間當作判斷,在分散式系統中時間是不可信的(除非學 Google 用原子鐘自幹出 TrueTime ),每個系統都存在著時鐘沒對齊的可能
- 多數節點有回應收到副本就算成功,少數節點晚回覆不會造成性能影響
3. What’s wrong with Paxos?
這一章節主要在描繪 Paxos 的背景與有多難理解的原因,但因為之前沒有學過 Paxos,就先略過這章
4. Designing for understandability
這一章節主要是作者不斷強調 understandability 是他們的核心理念,當遇到設計有多種方案選擇時,他們會選擇最好解釋給別人聽的那一個,對於他們來說可讀性是核心理念
具體上,透過 decomposition 拆分獨立模組以及減少不確定性與狀態可能性 達成目的,但在某一些部分還是有用上隨機性,因為這讓演算法更好理解
5. The Raft consensus algorithm
Raft 在實作上會先選出一名 Leader ,由 Leader 管理 log 的複製到其他節點的狀態機上,透過 Leader 的好處是不需要其他節點同意 Leader 能獨自決定新的 log 要儲放的位置;
如果 Leader 失敗了可以再選新的 Leader 出來
5.1 Raft basics
通常 Raft 集群會由五個節點組成,可以容忍兩個節點失敗,而每個節點有三種狀態 leader / follower / candidate,通常情況下是一個 leader 其他人都是 follower
- follower: 被動的處理來自 leader 或 candidate 的請求
- leader: 負責所有 client 的 request,並複製指令到 follower 中
- candidate: follower 發現沒有 leader,設一個隨機 timeout 切換成 candidate 模式,準備要選新 leader
下圖為狀態機示意圖
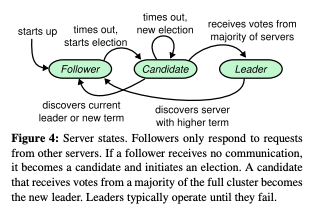
Raft 將時間切割成 回合 (term),每一個回合代表著一次的選舉,也就是 candidate 去競選 leader 的過程,如果成功推選出 leader 後,則每個節點紀錄這一個回合數;如果選舉失敗,則開啟新的回合直到有人成為 leader
以下為概念圖

回合本身是一個遞增數值,用來表示邏輯上的時間概念,有可能節點觀察到的回合跟其他節點不同,如果回合數小則代表自身的資料過時,他必須更新自己的回合數;
例如說原本的 leader 可能斷線,其他節點推選出新的 leader 則會進到下一個回合數,原本的 leader 回歸後發現自己的回合數比較小,則會主動變成 follower;
如果節點收到請求時,發現回合數比自己小,則代表請求過期,直接拋棄該請求
5.2 Leader election
Raft 透過 heartbeat 觸發 leader 選舉,當 leader 選上時,會在固定時間內發內容為空的 AppendEntries RPC 當作心跳包,如果 follower 超過 election timeout 沒有收到心跳包,則進入選舉階段
folower 會將現今的回合數加一便轉為 candidate,並請求其他 follower 投票給他 RequestVote RPC,遇到以下情況 candidate 才會改變狀態
- 贏得選舉
- 其他節點成為 leader
- 超過一定時間都沒選出 leader
贏得選舉
如果 candidate 拿下過半的票數,則成為新的 leader,每一個 follower 在同一個回合數下只會投票給請求先到的 candidate,這避免無效選舉的發生
如果 candidate 成為 leader,則開始發送心跳包
發現有其他 leader
如果在 candidate 階段收到心跳包(AppendEntries),則代表有其他 leader 產生,candidate 會去比對回合數至少要大於等於他自身的回合數,如果是則轉成 follower;
反之則繼續維持 candidate
超過一定時間都沒選出 leader
超過一定時間還是沒有選出來的話,timeout 後開始下一輪新的選舉
Raft 透過在一定時間內隨機 timeout (150-300ms),避免所有的 follower 同時進入選舉階段,這樣能加速 leader 的推選,後續會有更近一步的說明
在設計過程,作者曾考慮加入 rank ,rank 較高者更有機會成為 leader,但發現這會導致演算法設計更加複雜,且有可用性的問題,例如高順位 candidate 發生狀況,則低順位 candidate 要多一次 timeout 才能當上 leader 等問題
5.3 Log replication
Leader 會透過 AppendEntries RPC 將指令同步到 follower 並回傳執行結果給 client,如果 follower 此時 crash 等,leader 會持續送直到 follower 狀態同步
Log 是以 回合數 + 指令 的方式依序儲存,主要是檢視是否有不一致的狀況產生
每個節點都會保存現今最後一個 commited log 的索引 (commitIndex),Leader 在同步 log 時,會紀錄 log 要寫入的位置 (commitIndex + 1),並同時發送給 follower (leaderCommit),等到多數的 follower 都寫入 log 後才標記成 commited,Raft 保證 commited log 是已經持久化且最終每個 follower 都會達到一致性
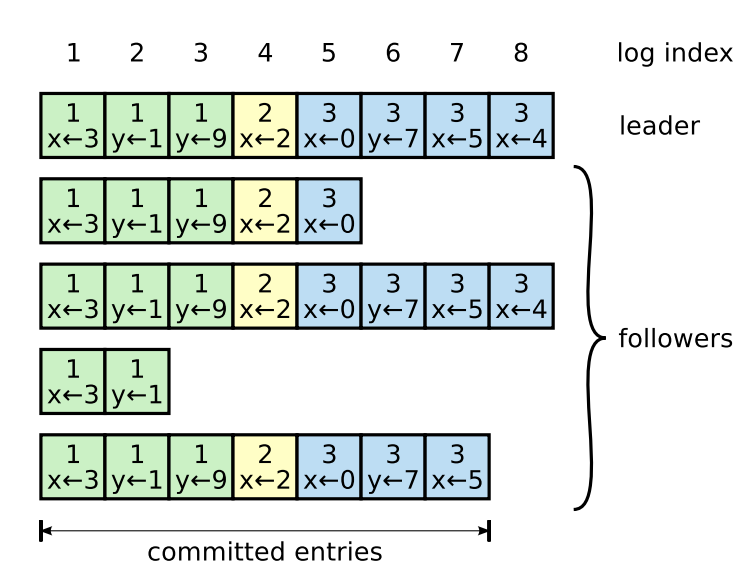
因此 Raft 保證 Logs 有以下特性
- 如果任意兩個節點的 log 有著相同的 index 與回合數,則他們必定儲存相同的指令
- 如果任意兩個節點的 log 有著相同的 index 與回合數,則該指令先前的 log 紀錄都必定相同
第一點保證節點儲存 log 後就不會再被改變,第二點則確保當 follower 發現自己的 log 跟 leader 不同時,可以依此重新跟 leader 同步紀錄
Leader 會針對每一個 follower 維護指針 nextIndex,用來記錄 follower 目前需要同步的 log 索引,leader 在發送 AppendEntries 指令時,會夾帶最新 committed log 的回合數與 index,讓 follower 可以比對 log 是否同步,如果 follower 在自己的 logs 中沒有找到對應的紀錄,則代表兩者非同步,回傳失敗,接著 Leader 不斷遞減 nextIndex 直到 follower 找到兩者最近一次同步的紀錄,接著開始一步步同步紀錄
leader 與 follower 找到最近一次同步紀錄的方式,可以優化成 follower 回傳這一個回合數下他所以紀錄的索引,leader 直接倒回這個回合開始同步;
但作者認為不一致狀態應該很少發生,優化的效益不大
透過這樣的 log 同步設計,Leader 在剛啟動時不用擔心太多同步的問題,利用 AppendEntries 的成功與失敗去調配 follower 儲存的紀錄,leader 也不用去刪除或更新自身的 log,讓整個同步的過程更加的簡單

5.4 Safety
先前介紹了 leader election 和 relicate log,但僅有這樣的機制是不夠的,試想如果 leader 發生錯誤,今天有一個 follower 僅包含部分的 commited log,選上 leader 後便會複寫原本其他已經 commited 的 log,這樣就不能保證一致性與持久化
這一章介紹 Raft 在 leader election 加上限制後,如何達到確保每一台狀態機都以相同順序保存相同的指令

Raft 會確保任何時候集群都符合上述條件
- Election Safety: 每一輪選舉至多只選出一位 leader
- Leader Append-Only: leader 從不刪除或改寫自己的 log,只會一直增加
- Log Matching: 任兩份 logs 在同一個 term 同一個 index 上,則 log 內容必定相同,且先前的 log 也都相同
- Leader Completeness: 某個 log 在任一一個 term 中認定 commited,則後續 term 中的 leader 都必須有該份 log
- State Machine Safety: 如果某個 server 在某 index 上的 log 套用至狀態機,則不會有其他的 server 在同一個 index 上套用不同的 log
5.4.1 Election restriction
在 leader-based 的共識演算法中,leader 最終會儲存所有的 commited log,在某些演算法中,leader 在沒有保存所有 commited log 情況下也能夠檔選,並透過額外的機制去回補這些未同步的 log,這增加了蠻多的複雜性
Raft 確保 leader 必須是由 擁有大多數節點同意的最新 committed log 的 candidate 才能當選,確保 leader 一定是擁有最新 log 的節點,只負責增加新的 log,讓資料流只有一個方向,省去其他的麻煩
在 RequestVote RPC 中增加了限制,RPC 中夾帶 candidate 最後一個 log 中的回合數與索引數,如果 follower 發現 candidate 的紀錄比自己舊,則回傳失敗

5.4.2 Committing entries from previous terms
先前提到,Leader 會等多數的節點儲存 log 才標記成 commited, 但如果 leader 將 log 寫到多個 follower 後,還來不及收到 commited 就 crash 了
此時新的 leader 會持續同步 log,但無法確認先前的 log 是不是被 commit 了,因為只有先前的 leader 才能確認 log 已經被多數的節點所保存
如以下圖示
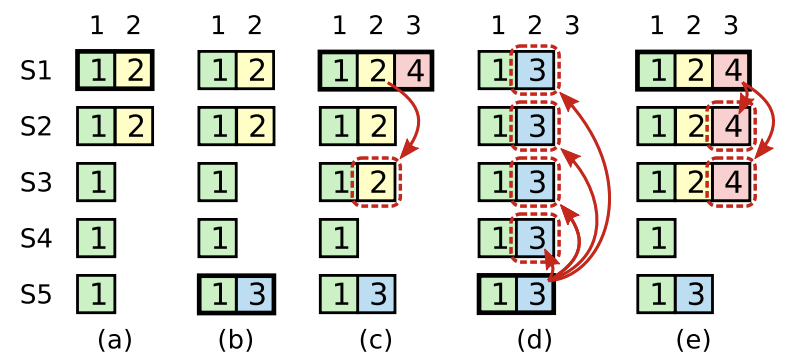
- S1 一開始是 leader,同步 term2 到 S2 就 crash
- S5 接著當 leader (S3,S4 可以投給他) 開始了 term 3,此時發生 crash
- S1 又回來當 leader,將 term2 的 log 同步到 S3 後,此時又 crash
接著拆兩種情況
d. S1 來不及同步 term4 資料,則 S5 有機會當入 leader,並用 term3 複寫掉其他資料
e. S1 同步 term4 資料到大多數節點上,則 S5 無法當上 leader
在 leader 還沒收到 commited 情況下,即使多數的節點已經同步 log,但新的 leader 有機會複寫
為了減少這樣的情況,Raft 不去計算先前 log 所同步的副本數去判定是否 commited,只有 leader 當下的回合數是透過副本的計算來決定 log 是否被 commited,如果 commit 後,則先前的所有 log 都被視為 commited,降低計算上的複雜性,並因為之前的 log 特性保證,先前的 log 一定也都被複製到其他副本上
5.4.3 Safety argument
更進一步解釋 Leader Completeness,透過反證法,找出集群無法不遵守 Leader Completeness
假設 leaderT 代表在 term T 的 leader,leader U 則是 term U,且 U 代表是 T 的下一位,且 leaderT 所認定的 commited log (logT) 在 leader U 不存在 (違反 Leader Completeness)
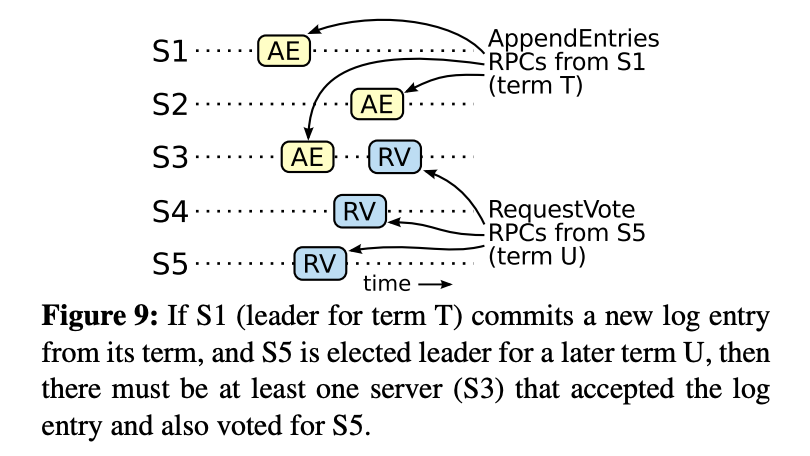
- leaderU 在當 follower 時並保存沒有 logT
- leaderT 將 logT 同步到多數節點上,而 leaderU 在選舉時獲得多數同意,也就是至少有一位投票節點 (voter) 收到 logT 同時又投票給 leaderU
- voter 必須先保存 logT,才又投票給 leaderU,反過來就不會有衝突 (term U > term T 所以 logT 後到會被丟棄)
- voter 依然保存 logT,因為 leader 從不改變既定 log,而 follower 也只有與 leader 衝突時才會複寫
製造出場景後,讓我們來看為什麼 Raft 不可能達到這樣的狀況
5. 依據先前規定, follower 只會投給 log 保留比自己更多的 candidate
6. 如果 voter 與 leaderU 最新一個 term 都是 T 的話,則 leaderU 的 log 數應該與 voter 相同,也就是 leaderU 至少擁有 voter 所擁有的 log
7. 反之,如果 leaderU 的最新 log term 大於 voter 的話,為了要符合早於 leaderU 的 leader 所有 commited log 都應該被保留到 leaderU 中,因此根據 Log Matching 則 leaderU 應該要儲存這些 log
在無法達成的情況,證明了 Raft 滿足 Leader Completeness 條件,確保 leader 如果最新的 log term > T,則 leader 必定擁有 term T 所 commited 的一切 log
Thus, the leaders of all terms greater than T must contain all entries from term T that are committed in term T
有了 Leader Completeness 屬性,就能進一步證明 State Machine Safety,如果某一機器在某一 index 套用指令到狀態機中,則其他機器在相同 index 下並然套用相同的指令,因為能夠被套用的 log 一定是 leader commited 後的 log,且因為 Log
Completeness,所有更新的 leader 也都保留被 commited 後的 log,因此能確保所有的節點終將以相同的順序套用相同的指令到狀態機上
5.5 Follower and candidate crashes
先前都是討論 leader crashed 後的處置,至於 follower 與 candidate 則單純很多,因為 Raft 的 RPC 指令都是 idempotent,leader 可以持續的送指令直到成功,follower 跟 candidate 失敗後重啟就重新接收指令就好
5.6 Timing and availability
Raft Safety 建立在不依賴 timing,系統不會因為訊息發送的快慢而得到不預期的結果;
但整體系統的可用性卻還是跟時間有一些關聯,例如說 server 不能再 election timeout 期間內票選出 leader,而 Raft 在沒有 leader 的情況下就不可用
所以整體上要符合以下不等式 Raft 才能運作正常
broadcastTime ≪ electionTimeout ≪ MTBF
broadcastTime代表 RPC 完整 request / response 所耗費的時間,須小於 electionTimeout 一個量級,通常在 0.5ms ~ 20ms;electionTimeout則是 follower 等待多久後會觸發選舉,這是可以主動去設定的,通常在 100ms ~ 500ms;MTBF則代表 server 進入錯誤狀態的區間,通常是數天至數個月
試想如果 broadcastTime > electionTimeout,則每一次選舉在還沒收到投票結果又開始下一輪選舉,則永遠選不完;
如果 electionTimeout > MTBF,則選舉還沒結束 server 又 crash,那也一樣會有 leader 無法產生的問題
總結
後續還有 Cluster membership changes / Log compaction / Client interaction 進階探討,就先暫時略過,僅理解前半部演算法的核心設計
分散式系統的迷人之處在於複雜,需要面對網路延遲 / 時間不一致(time skewed) / 機器失敗等不穩定的因子,「再不穩定的條件下架構出可容錯/高可用/一致性的穩定系統」,看似荒謬卻可以透過演算法的設計達成目的(或是說更貼近),實在令人讚嘆這些設計演算法的專家們
Raft 透過由 Leader 主導 Log 的同步,並加入選舉時的條件限制,確保 commited log 不會被改寫達到 強一致性;如果 Leade 失敗,也不用擔心 log 發生問題,等下一位 Leader 被推選出來又能夠繼續維持系統運作
整份論文讀起來還算蠻好理解的,確實符合作者不斷強調可讀性的重要