UUID 是一個被大量使用的演算法,分散式地產生大量不重複且固定為 128 bit的 ID,分散式是指說多台機器每秒同時產生多筆 UUID,有極大概率這些 UUID 都不會發生重複,不需要有一台機器居中負責 ID 的管控與發放,反例像是 MySQL 資料庫中的 auto increment id
先提重點,如何選擇 UUID v1 ~ v5,參考 Which UUID version to use?
- v4: 完全隨機,沒有特殊需求選這個,根據 uuid.js 統計有
77%用戶選擇這個 - v1: 組成包含 timestamp 與機器識別碼(MAC Address),如果需要識別由哪一台機器在什麼時間點產生可以選這個,根據 uuid.js 統計有
21%用戶選擇這個 - v5 & v3: 可以指定 Namespace 與 Name,相同的 Namespace 與 Name 會產生相同的 UUID,v3 雷同 v5,差別在於 v5 會採用 SHA1 當作 Hash function 而 v3 採用 MD5,除了相容性等考量,否則請優先採用 v5,根據 uuid.js 統計有
1%用戶選擇這個 - v2: 不採用,連 RFC 文件也只有帶到定義,沒有實作規範
需要特別注意,如果是使用 uuid.js 的 v1,uuid 實作是沒有採用 MAC Address,所以如果有識別同一台機器產生的 uuid 的需求,需要自己另外實作,後面有更詳盡的補充
以下將摘要 RFC 4122 - A Universally Unique IDentifier (UUID) URN Namespace ,並比對每週有將近四百萬下載的 uuid.js 實作,有詢問作者一些細節,他也非常熱心補充很多有棒的資料,會一並整理分享
RFC 4122
UUID 共有 128 bits,以下是 v1 實作規範
4.1.2. Layout and Byte Order
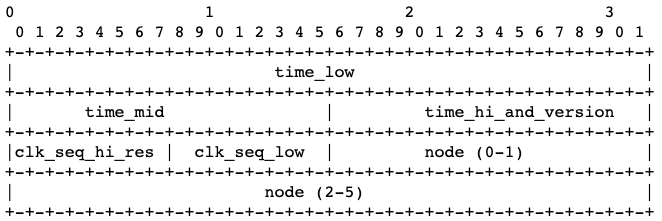
以下將介紹每個欄位的組成
4.1.3. Version
UUID 版本夾在 time_hi_and_version 最高效位元(most significant)中 4~7 bit,所以從 UUID string 就能看出版號
4.1.4. Timestamp
Timestamp 總共是 60 bits,對於 UUID v1 來說是 UTC 時間且自 1582/10/15 00:00:00 (the date of Gregorian reform to the Christian calendar) 開始計算,如果機器沒有 UTC 時間,可以採用 local time,但是要確保 local time 是穩定的
4.1.5. Clock Sequence
如果系統時間發生倒轉,或是 Node ID 發生改變,則會增加碰撞的可能性,所以透過 Clock Sequence 來紀錄,如果發現產生過的 UUID 採用的 Timestamp 比當下的時間還要晚時 (意即 Clock 時間被倒轉),則 clock sequence 遞增,初始化則隨機產生
另外如果 Node ID 發生改變,那最好也將 clock sequence 隨機重置,降低碰撞的風險
需注意 clock sequence 的設定最好是在系統啟動後設定一次就不要再改變,降低跨系統產生碰撞的風險
4.1.6. Node
Node ID 採用 IEEE 802 MAC address,如果有多個 MAC Address 任一挑一個有用的即可,如果沒有則隨機產生
以上是 v1 的欄位意義,v3、v5 則是把 Name 加上 Namespace 取雜湊,接著分配至上述的欄位中,v4 則全部隨機產生
4.2.1. Basic Algorithm
接著看最基本的演算法實作流程
- 取得系統級別的全域鎖
- 讀取系統設定檔,包含 clock_seq / node id / timestamp
- 計算出 timestamp
- 取得 node id
- 如果保存 node id 與讀取的 node id 不同,重新設定 clock_seq
- 當前 timestamp 小於保存的 timestamp,clock_seq + 1
- 將目前計算的值保存回去
- 釋放鎖
- 將目前的 timestamp / clock_seq / node id 組合出 uuid
如果要高頻率製造 uuid,會遇到以下幾個效能貧頸與對應解法
每次存系統讀取資料很沒效率:
僅需要再系統啟動時讀取一次進 memory 即可,假設系統沒有穩定儲存空間,則每次都要隨機產生 clock_seq,這會導致碰撞機率增加,應該要盡量避免;如果確定 node id 都不會變,也可以不用保存直接返回即可system clock 粒度不見得有到 100-nanoseconds:
System Clock Resolution:如果產生頻次不高,則直接將系統時間放大到 100-nano 的粒度即可,但如果系統單一時間產生過多 uuid,實作必須返回錯誤,或是暫停產生,直到系統時間正常,如果要提高粒度,也可以是在同一個系統時間內累計產生的 uuid 個數,每次要回寫系統資料很沒效率
只需要定時更新儲存資料即可,將 timestamp 設定在比至今產生的 UUID 使用的 timestamp 大一點,但又不要大到超過 reboot 時的所需要的啟動時間,目的在於降低 clock sequence 重置的機會,在下方的建議實作中是每 10 秒寫入一次
| |
跨進程分享狀態很沒效率
如果跨進程共享狀態很耗資源,可以每個進程切割一塊時間區段個別產生 uuid ,直到時間區段用完才去要新的
4.3. Algorithm for Creating a Name-Based UUID
v3 跟 v5 主要是在某一特定的 Namespace 下針對 Name 產生對應的 UUID,有以下特性
- 相同的 namespace 相同的 name,不同系統時間一樣有相同的 uuid
- 相同 namespace 下不同 name,uuid 不同
- 相同 name 不同 namespace,uuid 不同
- 如果兩個 uuid 相同,則代表 namespace / name 相同
UUID 欄位則是透過 Name + Namespace 雜湊後的值去派發
4.5. Node IDs that Do Not Identify the Host
如果 MAC Address 不能使用,有幾種做法能保證 Node ID 的獨一性
- 去跟 IEEE 聲請獨立區段的位址,在文件編寫時期價格是 US$550
- 使用密碼學強度的隨機碼取最低位 47 bit,最高 bit 設定為 1,主要是避開 IEEE 中 MAC Address 的區段
常見做法是在 buffer 中隨機累積一段資料,接著用 SHA1 或 MD5 取 48 bits,然後把最高 bit 設定為 1
6. Security Considerations
UUID 並不保證隨機性,所以不會很難猜,所以不能拿來做跟安全性有關的業務
Do not assume that UUIDs are hard to guess
以上大概挑個重點帶過
uuid.js 實作拆解
以下將閱讀uuid.js github repo的原始碼,在開始看 v1~v5 的實作前,先看一個用於產生隨機數的重要函式 rng.js
| |
程式碼很短,主要就是產生一個 rnds8Pool 陣列,隨機塞入數值,最後每次回傳 16 bit,如果這一段 rnds8Pool 都回傳了,就在一次產生新的隨機亂數
這可以保證產生 Generates cryptographically strong pseudo-random data.,來自 Nodejs 官方文件的保證,也是 uuid 不會有高碰撞機率的保證,切記 Math.random 不足夠隨機,拿來使用問題會很多
UUID v1 實作
以下挑重點說,不得不說作者的程式碼以及註解寫得很乾淨,直接標明實作對應的 RFC 段落
| |
先產生隨機數備用,在前面文件介紹中,有用到隨機產生的都會從 seedBytes 中提取
| |
這裡可以看到,實作中的 node_id是每次啟動時隨機產生,這符合文件 4.1.6,沒有採用 MAC Address 自己亂數產生也可以;
同時這一段我有特別留一個 Issue 詢問作者,為什麼不照文件規範去拿機器的 MAC Address,他回答到基於隱私問題,而且如果 Node ID 跟 Clock Seq 每次都隨機產生也是符合文件規範的
I believe that this comes close to the idea of the spec while avoiding the privacy problems that come with trying to derive a stable node ID from hardware.
| |
沒有 clockseq 就亂數產生
| |
如果實作者發現短時間內有太大量的 uuid 產生,需要拋出錯誤或是暫停 uuid 生成避免碰撞
| |
產生 time 相關欄位
v4 實作相當簡單,就是保留 version,其餘塞隨機數; v3,v5 大同小異,所以作者寫了一個 v35.js ,重點大概就這麼幾行
| |
把 namespace 跟 value 合起來然後 hash 過,接著就按照文件塞到對應的位置
後記:作者提交 proposal 給 tc39
作者在 PR 中有說到他提了一個 proposal 給 tc39 proposal-uuid,目前還在 stage 0,希望把 uuid 產生變成 js 的規範,主要是有太多錯誤且粗心的實作,例如使用 Math.random 等,這邊引用一篇非常棒的文章指出為什麼 Math.random 不好 TIFU by using Math.random(),以下將摘錄重點
TIFU by using Math.random() 文章重點摘要
TIFU => Today I Fucked Up
作者公司採用 microservice,但他們希望可以追蹤每個 request 在 service 中交互結果,所以需要有一個全域的 request id,需要一個隨機生成演算法產生足夠隨機的 id
所謂的足夠隨機包含兩點
- 足夠大的 identifier space:有足夠多的組合與可能性
- 足夠隨機的 identifier generation:有了足夠多的 identifier space,還需要足夠隨機的生成機制
作者決定用長度 22 的 base 64,也就是 space 有 64^22 這麼大,generation 則是用 decent pseudo-random number generator (PRNG) 常見的演算法,V8 即是採用這一套,如果足夠隨機,那這樣的空間足以預計每秒產生一百萬次也要三百年才會碰撞,多麼的美好
最後作者兜出來的程式碼如下
| |
看起來一點問題都沒有,也是大家常見的隨機生成做法
但是在不久後同事發現 ID 碰撞了 💥
“Anyone who considers arithmetical methods of producing random digits is, of course, in a state of sin.” From John von Neumann 意即要透過數學方式產生真正隨機根本是不可能
PRNG 實作
簡單看一下偽隨機數的生成方式之一 PRNG (pseudo random number generator)
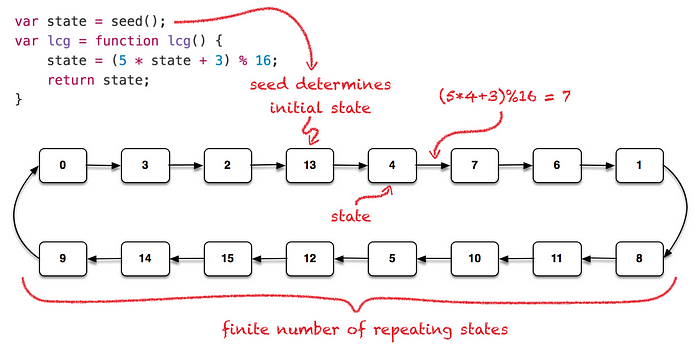 來自原文的圖片
來自原文的圖片
簡單來說就是會有一個初始的 Seed,接著按照數學公式算出一個對應的位置,所以只有經過幾次輪轉,所以要用 finite state 產生隨機數是不可能的,只要 PRNG 持續產生,那最終輸出會重複出現 Periodic,作者比遇到, PRNG 就像一本壓縮的密碼本本包含著一串數字,Seed 像是你挑某一頁開始看,接著一路往下翻,到書尾再從書首開始看起,終將輪迴
不過只要 Cycle 的長度長到在有限時間內不會發生即可,這也決定 PRNG 演算法品質,稱之為 full-cycle generator
If a PRNG’s state has a k-bit representation, the cycle length is less than or equal to 2ᵏ. A PRNG that actually achieves this maximum cycle length is called a full-cycle generator.
良好的 PRNG 會盡可能達到 2ᵏ 上限
後面有一段再說明 Chrome 當時的 Math.random 演算法錯誤,所以實際上 590 million 就會發生循環,更糟糕的是基於生日悖論,產生僅僅 3 萬次就會有 50% 的碰撞機會 (50% chance of collision after generating just 30,000 identifiers.)
最後的結論是如果要採用偽隨機生成數請用 CSPRNG(cryptographically secure PRNG),或是採用系統核心基於外部噪音、網路封包等產生的真隨機數 urandom
其他
今天路過看到一篇關於 UUID 的好文 閒談軟體架構:UUID,主要更深入探討如果把 UUID 當作資料庫的 Key 對於效能的影響,主目的是希望能達到 分散式產生遞增的 Key,UUID v1 算是有符合這個要求,但因為有做過 timestamp 的拆分,導致 Java 實作在比對時會有點問題
可以自己客製化 UUID 的格式,或乾脆自創,參考其他實作如 Twitter Snowflake(已 deprecated) 或是 Firebase Push ID,大抵上都脫離不了 timestamp 加上亂數或是加上機器識別碼的做法
結論
ID 是常用的屬性,用來抽象化指向某個物件/事件,選擇正確的方式產生 ID,才不會對於系統產生效能貧頸,透過學習 UUID 的實作過程,看到分散式產生 ID 的方式,尤其是在大數據時代,快速產生獨一(且遞增)的 ID 尤為基礎且重要,而在之中隨機性在整個過程扮演著很關鍵的角色