最近想了解一下作業系統處理 I/O 的過程,翻閱到 CloudFlare 一系列關於作業系統與 Network Packet 處理的實驗與文章,蠻有趣的稍微整理了一下
關於 Linux 封包處理
主要在量測 Linux 極限可以處理多少 packet per second / 以及如何持續優化
Linux 單機處理 1M udp packet per second
文章出自:How to receive a million packets per second,在硬體規格
| |
可以撐到每秒接收一百萬個 udp 小封包(32 bytes),發送跟接收端在同個區網的不同機器上
中間的嘗試迭代過程很有趣
1. 裸測
僅能到 0.19~0.35 M,發現 kernel 可能隨機分配 process 到不同 CPU 上,透過 taskset 指定 CPU 運行,穩定在 0.35 M 上不去,發現只有單一 CPU 忙碌到 100%
2. NUMA 架構優化
多核心處理器為了避免多核心在存取 Memory 的貧頸,會採用 NUMA 架構,讓一至多個 CPU core 共用一塊 memory 組成一個 NUMA node;
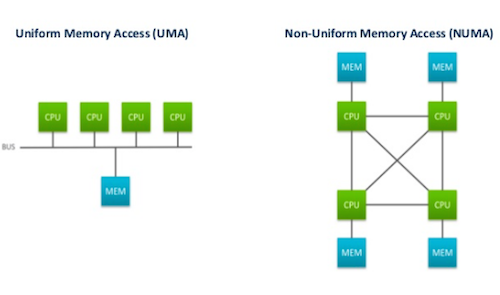
- 圖片出處 @lkmem/SkWYoA-TU
NUMA 好處是如果 CPU 都只存取 local memory 效率會非常好,如果要存取到不同區域的 memory 或是任務在不同 NUMA node CPU 中 context switch 則效率會很差,作者進行以下比較:
- 如果 RX queue 和應用程式是在同一個 NUMA node 的不同 core 上,效能是最好的
- 如果是在不同的 NUMA node 上,則效能差且不穩定
- 如果是在同個超執行緒(HT)上,則效能只剩一半
3. 增加 NIC 的 RX queue 數量
過往 NIC 只有一個 RX queue 用來存放接收到的封包,而一個 RX queue 只能由一個 CPU 讀取限制了多核心機器的效能,所以 NIC 目前都會有多條 RX queue
但是有了多條 queue,NIC 需要把同一個 connection 的多個 packet 送到同一個 queue 中讓同一個 CPU 處理,否則會遇到 packet order 亂掉的問題,此時可以透過 hashing 解決,hash function 為 {ip, port}
後來因為實驗的 NIC 無法調整 hash 機制,所以改用增加 IP 的方式,但目的也是要把 packet 分散到多個 RX queue 上,此舉增加到 0.47M
4. 加開 recv thread
原本是用 single thread 接收,嘗試開啟 multi thread 但反而性能下降,原因是多個 thread 共用同一個 file descriptor 需要額外 lock
但好在 Linux 在 3.9 後加入了 SO_REUSEPORT 可以讓多個socket descriptor 綁定到同一個 port 上,所以讓多個 thread 可以分擔讀取的工作,但作者同樣觀察到 SO_REUSEPORT 這一層同樣有分散不平均的問題,只有幾個 CPU 特別忙碌
One of the features merged in the 3.9 development cycle was TCP and UDP support for the SO_REUSEPORT socket option; that support was implemented in a series of patches by Tom Herbert. The new socket option allows
multiple sockets on the same host to bind to the same port, and is intended to improve the performance ofmultithreaded network server…..…. Incoming connections and datagrams are distributed to the server sockets using a
hash based on the 4-tuple of the connection—that is, the peer IP address and port plus the local IP address and port.
小結
單機 Linux 優化後可以做到每秒接收 1M UDP packet
- 記得將 packet 分散到 RX queue
- 接收端應用程式要打開 SO_REUSEPORT 並透過 multi thread 讀取
- 要有多的 CPU 負責從 RX queue 讀取
- 如果是 NUMA 架構,RX queue / 應用程式的 CPU 要在同一個 Node 性能比較好
為什麼我們需要 Linux kernel 處理 TCP stack?
文章出自:Why we use the Linux kernel’s TCP stack
為什麼我們需要 OS
試想一個問題,如果我們一台 server 上只跑一個專用的應用程式,那為什麼我們需要先額外安裝一個上千萬行的 OS 去代理執行我們的應用程式?
OS 主要提供幾個好處:
- 抽象化硬體、提供統一介面:
OS 會抽象化底層的硬體,讓應用程式專注於開發而不用管實際執行的硬體為何,帶來更好的移植性 - 資源管理:
OS 可以透過排程讓一個硬體於多個應用程式間切換使用,而不會有一個應用程式霸佔整個硬體資源,例如網卡可同時處理 server request 也可用於 ssl sesson
為什麼需要 userspace TCP stack
如果透過 OS 則讀寫硬體資源時需要涉及 user space / kernel space 資料的複製與 context switch,這會帶來額外的 latency / CPU performance 影響
例如 Google、Cloudflare 這種網路流量非常大的公司,就會有動機去客製化 TCP stack,所謂的 userspace TCP stack 就是 繞過(bypass) OS Kernel直接存取網卡,這張網卡就專門被單一的應用程式所使用,OS 的監控工具 (iptable/netstat) 等都無法使用,其他應用程式也都不能
Cloudflare 有提到透過 Linux iptable 大概可以處理每秒一百萬的 packets,而 Cloudflare 在遭遇攻擊時流量會在 單台 server 每秒三百萬的 packets,這也是他們需要繞過 kernel 自行處理的動機
但目前沒有穩定的 open-source userspace TCP stack 可以使用,要自己維護開發,除了執行外周邊的 debug、monitor 工具都要自己想辦法成本很高,所以 Cloudflare 採取半繞過的方式,只有 “RX queue” 會繞過 kernel,這帶來的好處是享有一定的效能提升且其餘 packets 處理能仰賴既有的工具如 iptables/netstat
優化 latency
文章出自:How to achieve low latency with 10Gbps Ethernet
前面優化了 throughput,現在要來看 latency 如何被優化,量測的基準線從平均 47.5 us 開始
1. 提高 read 的頻次
Linux 3.11 開始增加了 SO_BUSY_POLL 的 socket 選項,在指定的時間內 kernel 就會去讀取 packet 提升讀取的頻次,透過增加 CPU 使用率降低 latency 7 us
同樣的道理可以套用在 user space ,透過 non-blocking read fd.recvmsg(MSG_DONTWAIT) 再往下降低 4 us
2. pin process
透過指定 process 在特定的 CPU 上執行減少 context switch,降低 1 us;
但如同先前提到,預設一個 RX queue 只能有單一 CPU 讀取,如果剛好應用程式也在最忙碌的 CPU 上,則延遲反而會增加 2 us
3. 將 RX queue 綁定到指定 CPU
為了避免上面問題,可以透過 Indirection Table 調整 RX queue 如何分配到 CPU 讀取,作者限定只有在同一個 NUMA node 的 CPU 才能讀取 RX queue
同樣的做法也可以用 Flow steering 實作,指定特定的 flow 到特定的 RX queue 上面,額外用途是確保在高流量情況下指定的封包還能被特定的 CPU 處理,如 SSH/BGP,也可以用來防堵 DDoS 攻擊
| |
在傳送端也可以指定類似的事情,調整 TX queue 透過哪個 CPU 發送的機制
小結
再通過一些優化,從原本 47 us 降到 26 us;如果是透過 bypass kernel 則近一步下降到 17 us