DDIA - 《Designing Data-Intensive Applications》,這本書值得有一個專門的縮寫 XD 在幾年前剛出社會時有先硬啃了大半部分,在往後的工作上這些觀念不斷的被使用上,一直很想再重新更深入理解這本書;
剛好最近要開始準備公司內部分享,分享一些關於資料庫的事情,重新翻閱這本書,並寫下讀書心得,以下內容包含圖片都是整理自相關資料
以下將描述
- 最簡單實作資料庫的方式
- SSLTable / B Tree 儲存方式與比較
- Column Storage
Storage and Retrieval
資料庫最基本的核心功能
- 給你一些資料,幫我保存 - storage
- 我晚點跟你拿這些資料,記得給我 - retrieval
如果僅考慮這兩個功能,如何用最簡單的方式實作呢?
一. 最簡單的資料庫 - Log Structured Storage
今天實作一個 key-value DB,我們用兩個 bash command 就可以完成
| |
呼叫 db_set 時,很單純一直把值 append 到檔案的最後;如果要取出,則從檔案的最後開始比對 key,回傳第一筆匹配的值,這樣就能解決同個 key 被更新多次的狀況
| |
如果我們考量寫入與讀取的效能
- 寫入:非常好,因為是順序性寫入,基本上沒有比 append 更快的寫法,在非常多的應用程式中,也都用上
append only log,如 MySQL binlog - 讀取:因為要從檔案最末端開始讀取,時間複雜度為
O(n),非常慢
1. 改善讀取效率 - 加上 Index
我們可以透過在 memory 中維護一份 Hash Table,在寫入時順便儲存 { key:檔案位置 },這樣就能在查詢時用 O(1) 的時間找到 key
但這帶來另一個限制,
Hash Table 必須能完整放入 Memory,如果今天 key size 超過,則 Index 無法被建立就會回到 O(n) 的查詢複雜度
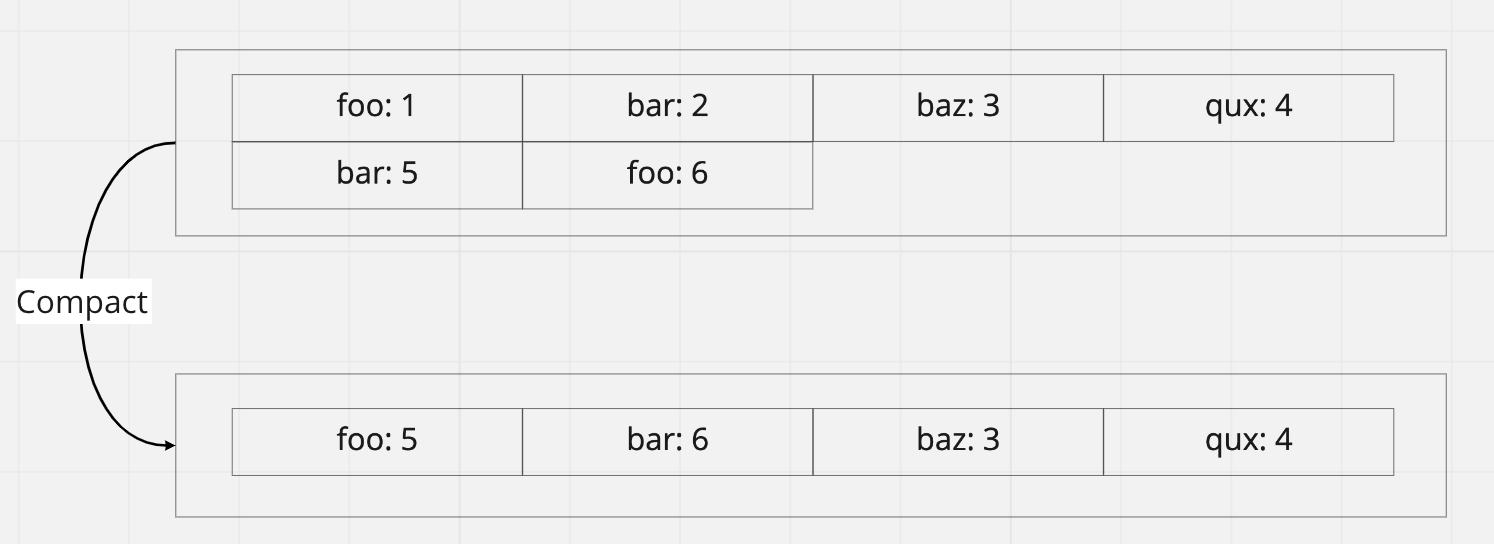
2. 改善儲存效率 - Compact
思考另一個儲存問題,今天如果是同一個 key 被反覆儲存多次,以目前 append-only 的設計,他會被儲存很多筆,每次讀取只拿最後一筆,前面幾筆的資料空間就浪費了
所以通常會搭配 Compact 設計,重新整理 log 把舊資料刪除,釋放儲存空間,實作上 會開新的檔案合併舊的檔案內容,並不會直接修改舊檔案,這樣做的好處是寫入、讀取不會中斷,等到新的檔案完成後,再移除舊檔案
3. 為什麼要用 append 而不是直接 update ?
如果我直接改原本的資料,是不是就節省了 compact 的過程?原因在於硬碟順序寫入效能會比較好,即使 SSD 也是,這點後續補充
4. 無可避免的缺點 - range search
如果要範圍搜尋,Hash Table 無法做到這件事,同樣的 disk 儲存方式也沒有排序,所以只能全部 Scan
5. Real World Sample: Bitcask
以上的方式聽起來簡單的過分,但這也是真實有在採用的作法,如 Riak 內的儲存引擎 Bitcask,Riak 是分散式 Key-Value DB
Bitcask 是用 Erlang 實作,原始碼 有點看不懂,但有另一篇文章可以從 high level 角度去查證 Bitcask: A Log-Structured Hash Table for Fast Key/Value Data
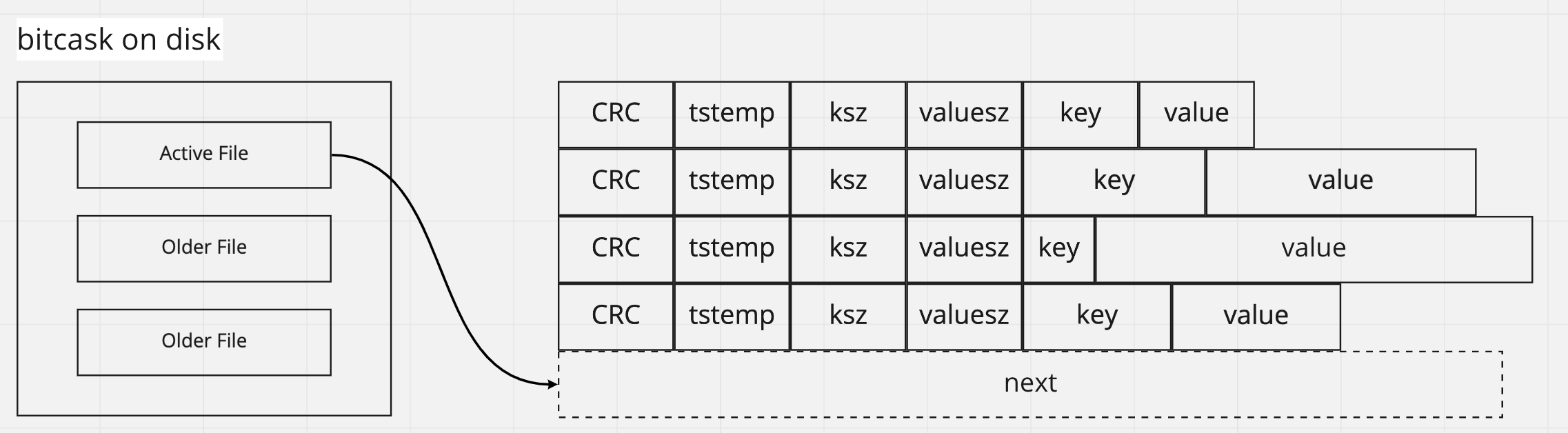 儲存方面,bitcask 維護一個 active file 持續寫入,其餘會有多個 older file 只讀不寫,背景運行一個 merge process 持續合併多個 older file
儲存方面,bitcask 維護一個 active file 持續寫入,其餘會有多個 older file 只讀不寫,背景運行一個 merge process 持續合併多個 older file
每筆資料有前綴 metadata,這些資料欄位的尺寸都是固定的,但是 key value 的長度可以是變動,透過 keysz / valuesz 知道對應長度;
其中 CRC 是 checksum,可以檢查資料寫入是否有誤
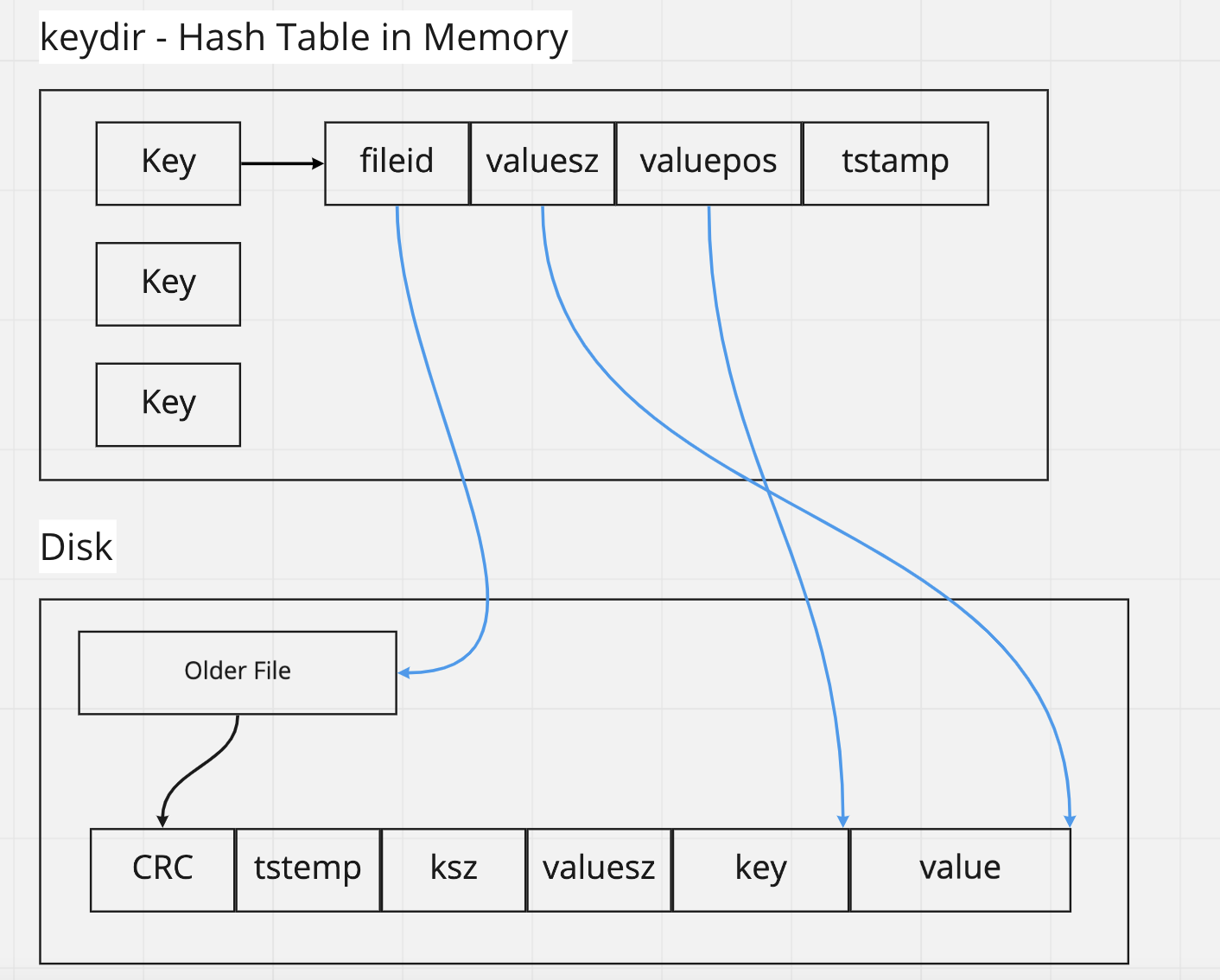 bitcask 中的資料結構
bitcask 中的資料結構 keydir 就是 hash table,保存 key 對應到 value 的儲存位置,這樣就能夠一次 Disk 查詢取出 value
6. 不同面向考量
資料庫不單是讀寫,還需要考量其他面向的問題,讓我們一一檢視這樣的簡單設計
- Crash Recovery: 基本上不會有問題,因為檔案都是 append only,如果有問題可以透過 CRC 檢查,只是 keydir 要重建
- Restore: 直接複製檔案過去就好
- Heavy Load & High Volume: 當資料量變大或是 loading 變大時,預期 bitcask 的效能不會有太大差異,因為都是很簡單的 disk 與 memory 操作
二. SSTable 與 LSM Tree
上面提到 Log Structure 遇到 range search 效能會很差,那如果我們把資料排序後再寫入呢?
在計算機科學中,負責快速插入、查找、範圍搜尋的資料結構可以用 平衡樹,插入與搜尋都是 O(logn),如果是範圍搜尋則為 O(logn, k)
實作上,當資料寫入時
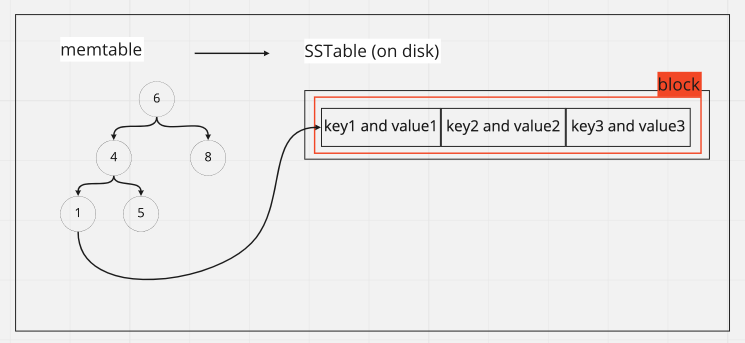
- 會先暫存到 memory 中,資料結構為平衡樹,此稱為
memtable - 當 memtable 超過門檻,寫入硬碟,稱為
SSTable (Sorted String Table),後續資料寫入新的 memtable - SSTable 同樣會在背景 compact,如 Log Structure
到底儲存用 sorted 後的結果有什麼巨大的好處?又會有帶來什麼影響呢?
讓我們思考以下幾個細節
1. 寫入最一開始是儲存在 memory 中,如果 crash 會不會掉資料?
會,所以寫入 memory 時同時會用 append log 方式寫入資料庫,借用 log structure 的智慧,當 crash recovery 從 log 復原即可
2.sorted 後儲存結果的幾個好處
除了剛剛說的支援更快的範圍查詢外,保存在 memory 中的 index 數量可以更少,讓 dataset 支援容量更大,如上面圖示,SSTable 會以多筆資料為一個 block保存,今天我要找 2,index tree 內沒有 2 沒關係,我可以找到 1 的檔案位置,接著把 block 讀取出來,這樣我就能透過 1 找到 2,能夠這樣找是因為 儲存有按照 index 排序
3. compact 過程會不會很麻煩?
不會,如果有學過 merge sort,這個過程就是把兩個小的 block 從頭到尾 iterate 過就解決了,時間複雜度為 O(n+m)
4. 查找不存在的 key 效率不好
因為要找過每一個 SSTable 才能確定資料不存在,這邊可以利用 Bloom Filter 快速判斷,可以參考我之前的筆記 Sketch Data Structure - Bloom Filter 介紹與實作
5. Real World Sample: LevelDB / RocksDB / BigTable
Google LevelDB 是用 SSTable 概念實作的 Key-Value DB,可以參考他的說明 LevelDB impl.md,其中可以注意 compact 過程是有分等級的 (所以才叫 level DB),避免一次性大量的 compact 發生導致硬碟效能吃不消,其中翻了一下 memtable 沒有看到是用什麼方式實作
RocksDB 則是 Facebook 基於 LevelDB 所開發的,說明蠻完整的 RocksDB Overview
The memtable is an in-memory data structure - new writes are inserted into the
memtableand are optionally written to the logfile (aka.Write Ahead Log(WAL)). The logfile is a sequentially-written file on storage. When the memtable fills up, it is flushed to asstfile
下方有提到一些 memtable 實作與比較,預設是 skiplist,感覺蠻有趣的,未來可以再深入研究
另外還有 Google 的Bigtable: A Distributed Storage System for Structured Data,裡面也有提到很多相關的內容,未來待讀項目之一 (挖坑)
以上 Log Structure 與 SSTable 都可稱為 LSMTree,也就是 Log Structure and Merging Tree,透過 log 方式儲存並有持續 merge 的行為
三. B Tree
B Tree 在資料庫儲存上是非常受歡迎的選項,如 MySQL / PostgreSQL 等,B Tree 也是平衡樹的一種,每一層保存指定數量的節點 (branching factor) 代表不同的範圍,並保存指向下一層的指針,最後在葉子節點 (leef node) 保存資料
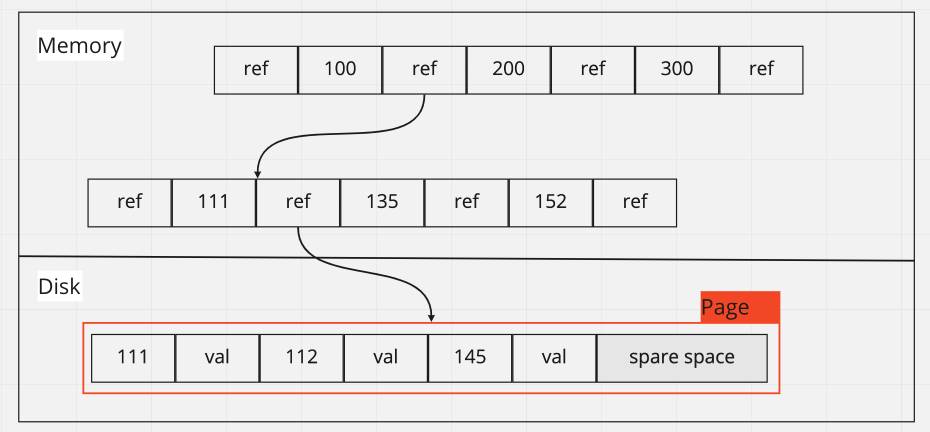
在 B Tree 的保存中,是以固定尺寸的 Page 為單位,剛好對應到硬碟儲存方式也是以固定尺寸的區塊儲存,如果資料沒有塞滿 Page 則會造成一些破碎
高度為 4 + brancing factor 為 5 + Page size 4 KB 的 B Tree 就能儲存 256 TB
B Tree 與 SSTable 相似之處在於資料保存於硬碟都是排序過,但是 B Tree 會不斷修改已經持久化的檔案,尤其是當 Page 內資料超過需要拆分 Page 並重新平衡時,會有比較多的硬碟操作,而 SSTable 只會一直寫入等到 compact 階段才合併產生新的檔案
B Tree vs SSTable
常理來說 SSTable 寫入會比較快,因為就是 append 上去而 B Tree 需要先寫 WAL 並等到 Page 刷新到硬碟上,這點在高寫入的系統下尤為重要; 另外 SSTable 會有 compact 過程,相比 B Tree Page 設計可以更有效使用磁碟空間
而 B Tree 的好是讀取較快,因為 SSTable 的同一個 key 可能散落在多個 file 中需要每個都檢查;同時當遇上 compact 時效能會有比較大的衝擊,而 B Tree 相對會比較穩定
Column Storage
上述偏 OLTP 的資料庫設計,資料是以 row 的方式儲存,但是在 OLAP 專門做分析上,往往我們需要的是 query 非常多的資料筆數但只分析其中一兩個欄位,例如撈出過去一年的銷售總額,如果資料是以 row 方式儲存,要把一整年的資料都拿出來過濾、篩選再總和,十分耗費資源
在 OLAP 中,既然我們常常以 column 為主,那改用 column 來當作儲存的依據是不是會比較好? column storage 的概念就這樣延伸出來
這樣做的最大好處非常好壓縮,從欄位資料的 cardinality 來看,往往數量不多,例如數百萬筆資料中國家種類就那兩百個,所以可以用一些壓縮的技巧如 bitmap encoding,用 bitmap 代表某個特定值儲存,在讀取時可以用 bitwise 操作,對於 CPU 效率會好上許多;
所以儲存空間小、運算也很快
限制與應變
因為現在是每一個 column 都獨立儲存,那如果我想要讀取某一個 row 的所有 column 怎麼辦?
所以在儲存時每一個 column file 的 row order 都必須一樣,這樣才能還原同一筆 row 的全部 column
如果在儲存時希望有排序,例如分析資料通常會按照日期排序,可以套用之前 SSTable 概念,先用 memtable 排好序,寫入時再分成多個 column file 儲存

要注意 column-family database 與 column storage database 是不一樣的詞彙,如 Cassandra 在文件表明是以
row-based儲存,參考 Apache Cassandra is a highly-scalable partitioned row store,但他被歸類在 column-family 中,至於為什麼這樣歸類可能是跟他的用途跟印象比較有關,網路上隨便一查都有一些錯誤的資訊,要在小心留意 (會不會我才是錯的 ?! 如果是歡迎留言讓我知道)
結論
知道資料庫怎麼儲存好像不會變成資料庫大師 XD 但對於未來在評估不同的資料庫時,又多一個可以驗證真偽的工具,尤其是在大營銷時代各種新的技術名詞持續被發明,但資料庫的本質就還是 storage and retrieval