關於 MySQL Lock 來來回回寫了也有幾篇,每次看都有不同的發現,這次為了準備公司內部分享,重新再翻閱一次又找到一些新的有趣發現,以下將盡可能完整的解析 MySQL Lock 與 Index 的關係,怎樣的查詢會拿到怎樣的鎖,以及怎樣的查詢又可能互相 Deadlock
文章主要受啟發於 解决死锁之路(终结篇) - 再见死锁,對應的實驗可以看程式碼 sj82516/mysql-deadlock-test,先說結論,在 DML (更新、刪除、插入)的操作中,Lock 會與套用的 Index 有關,在 MySQL 中 Index 有幾種
- Clustered Index:
通常是 Primary Key - Unique Secondary Index:
如果沒有 Primary Key,則 Unique Secondary Index 會是 Clustered Index,行為與 Clustered Index 雷同,不額外贅述 - Non Unique Secondary Index
以下將重點分析 Clustered Index / Non Unique Secondary Index 對於 MySQL 操作有什麼不同的影響,在 Read Committed 簡稱 RC) 與 Repeatable Read (簡稱 RR) 下又有怎樣的不同行為,實驗預設是 5.7 + Repeatable Read (MySQL 預設)
Clustered Index
先來一題簡單的暖身題,以下兩個 Transaction 為什麼會 Deadlock
 要滿足 Deadlock 需要有四個條件
要滿足 Deadlock 需要有四個條件
- no preemption
- hold and wait
- mutual exclusion
- circular waiting
在上面的案例中,MySQL 在 RR 下要 update 會先取得 exclusive lock,兩個 Transaction 手上都拿了對方想要的資源卻也不都會先放開手上的鎖,導致 Deadlock
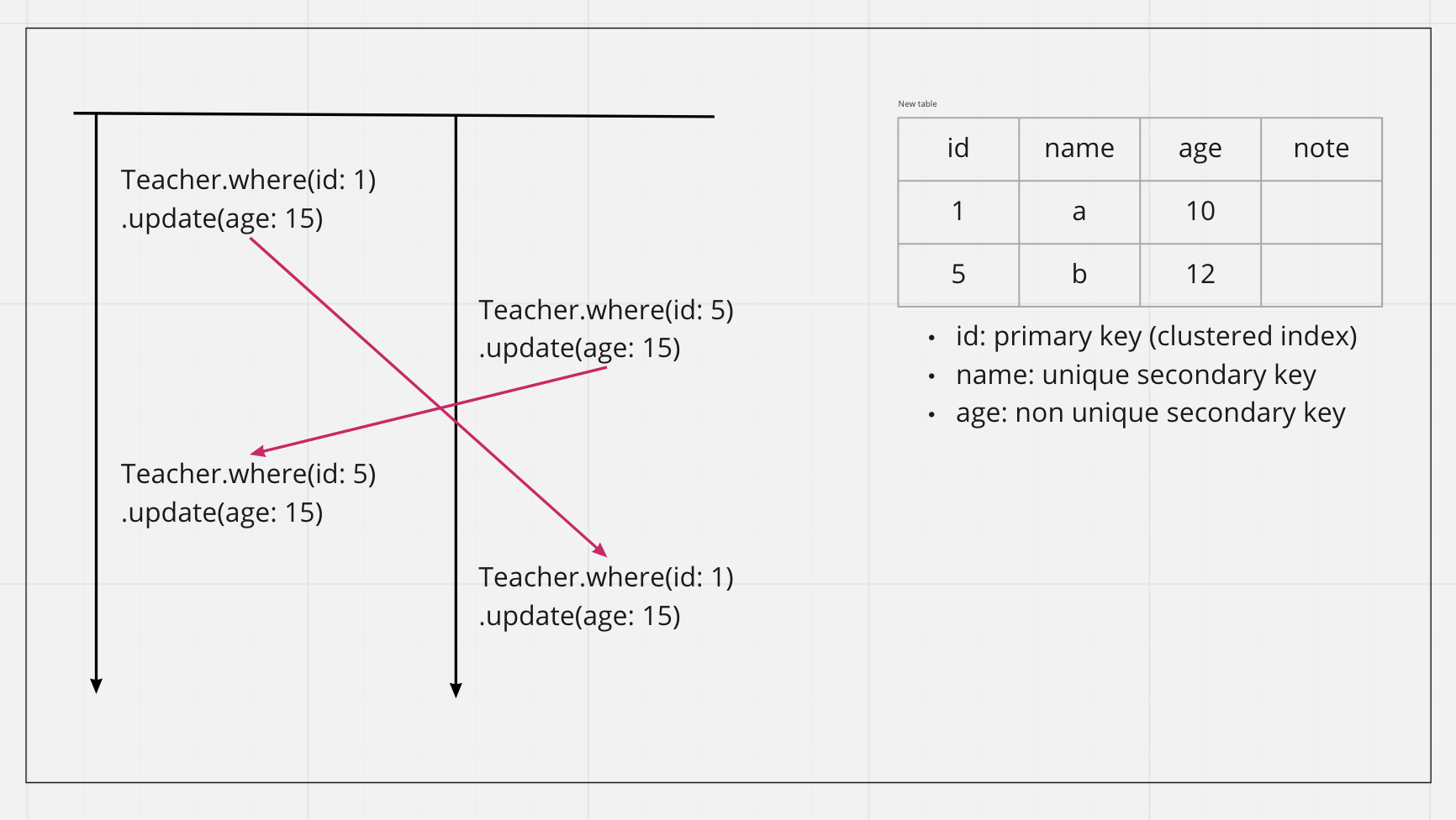
直接從圖片很容易看出彼此 Deadlock,但正式環境中多筆 Transaction 交雜,該如何找出 Deadlock 呢?
1. 如何 Debug Deadlock
MySQL 有幾個相關參數
- innodb_deadlock_detect: 是否偵測 deadlock,預設開啟
- innodb_lock_wait_timeout: 如果沒有開啟 Deadlock detect,建議設定較短的 wait timeout 否則會一直等到
- innodb_print_all_deadlocks: 將所有 Deadlock 錯誤輸出至 error log
如果沒有輸出 Deadlock error,可以用 > SHOW ENGINE INNODB STATUS 輸出,其中有兩個區塊 deadlock 顯示最近一筆 deadlock 錯誤,transaction 則會顯示目前在等待 lock 的 transaction
1.1 實際閱讀 Deadlock
| |
這部分內容參考 MySQL死锁问题如何分析,重點看這一段
RECORD LOCKS space id 275 page no 3 n bits 72 index PRIMARY of table test.teachers trx id 9596 lock_mode X locks rec but not gap waiting
專指 row lock
Record lock, heap no 2 PHYSICAL RECORD: n_fields 6; compact format; info bits 0 0: len 8; hex 8000000000000001; asc ;;-> index,用 16 進位表示,這邊是指 id: 1
,我們可以從 log 中看出操作 / 手上的 lock / 等待的 lock / Lock 在哪一個 row
2. 取得 Lock 的順序性
如果查詢的條件命中多筆,那 Lock 會怎麼取得呢? 接著看以下案例
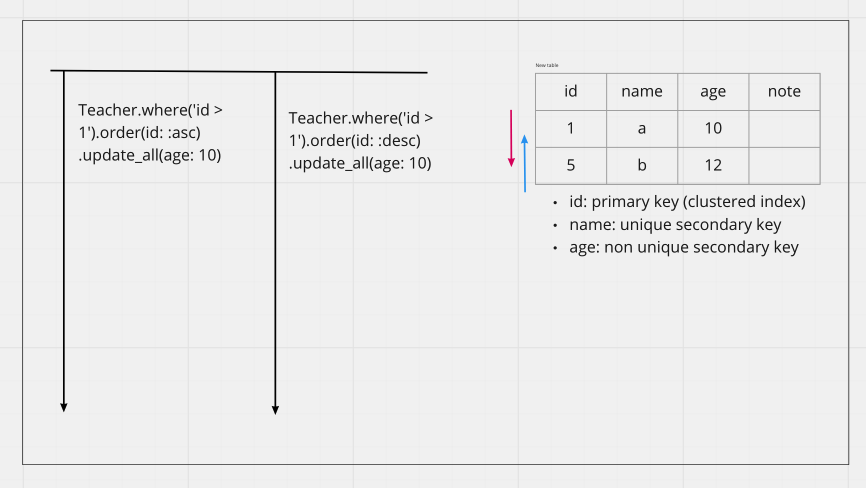
根據 MySQL 文件,會根據 Order By 的指定條件與 Index 本身順序性一行一行鎖起來
If an UPDATE statement includes an ORDER BY clause, the rows
are updated in the order specified by the clause. This can be useful in certain situations that might otherwise result in an error. Suppose that a table t contains a column id that has a unique index. The following statement could fail with a duplicate-key error, depending on the order in which rows are updated
從 Deadlock Log 可以清楚看到 id 2 / id 5 被互相鎖住
| |
2.1 建立 Index 時決定順序
當建立 MySQL Index 也可以指定順序,但需要注意 MySQL 5.7 會忽視 (全部都是 asc) 只有在 MySQL 8.0 以上才支援,所以以下案例只發生在 MySQL 8.0
我們可以透過 USE INDEX() 指定執行時的 Index

(5.7 文件) A key_part specification can end with ASC or DESC. These keywords are permitted for future extensions for specifying ascending or descending index value storage. Currently, they
are parsed but ignored; index values are always stored in ascending order.
2.2 恰巧兩個 Index 順序相仿
2.1 案例中我們很刻意讓 Index 同一個欄位欄位但順序剛好相反,但如果是兩個不同 Index 而資料寫入時讓順序恰好相反呢? 在建立資料時,id 跟 name 的順序剛好相反,也就是
| |
這樣也會發生 Deadlock!

3. 查詢沒有命中 : Gap Lock
如果查詢沒有命中,此時 MySQL 在 RR 情況下會取得 Gap Lock,所謂的 Gap 是在已存在欄位之間的縫隙,為了避免幻讀 MySQL 會鎖住 Gap 不讓其他 Transaction 插入資料
這邊特別介紹兩個鎖定區間的 Lock,分別是 Gap Lock / Insert Intention Lock
- Insert Intention Lock 故名思義是是插入前會鎖定該區間
- 這兩種 Lock 特別在於不會排擠自己人,例如
Gap Lock 不會阻擋 Gap Lock/Insert Intention Lock 不會阻擋 Insert intention Lock,但是Insert Intention Lock 跟 Gap Lock 互斥,原因是區間可能很大,為了提升性能,在同一個區間可以同時插入新資料,如果真的有違反 Unique Key 則會有原本的重複性檢查阻擋,Update 也是
有一個場景是「我們希望更新某一筆資料,發現資料不在則寫入」,如以下範例則會造成 Deadlock
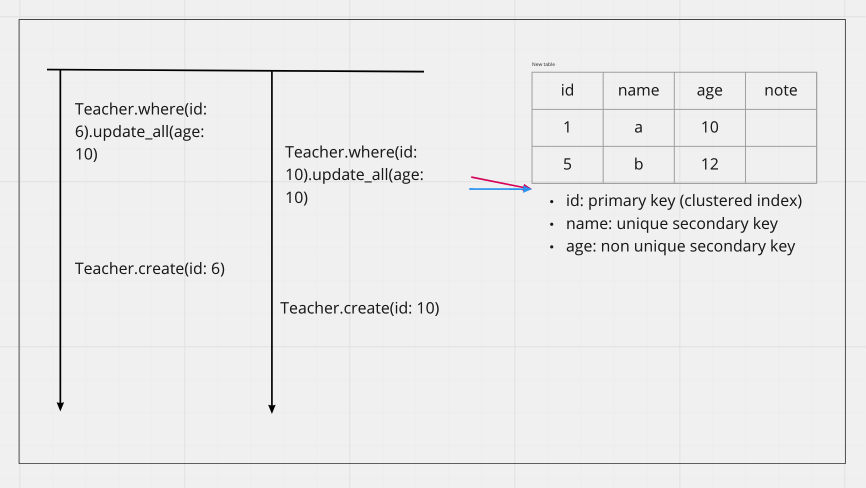
因為 id 6 / 10 在 update 時都取得了 Gap Lock,接著要 Insert 取得 Insert Intention Lock 卻因為雙方都還握有 Gap Lock 而無法寫入,讓我們看具體的 Deadlock 細節
| |
可以看到雙方都在等 lock_mode X insert intention waiting,指定的 row 是 supermum 這是代表最後一個區間,區間大致長以下這般
| |
所以同樣的 query 只是原始資料改變落在不同區間,就不會有 Deadlock 如以下
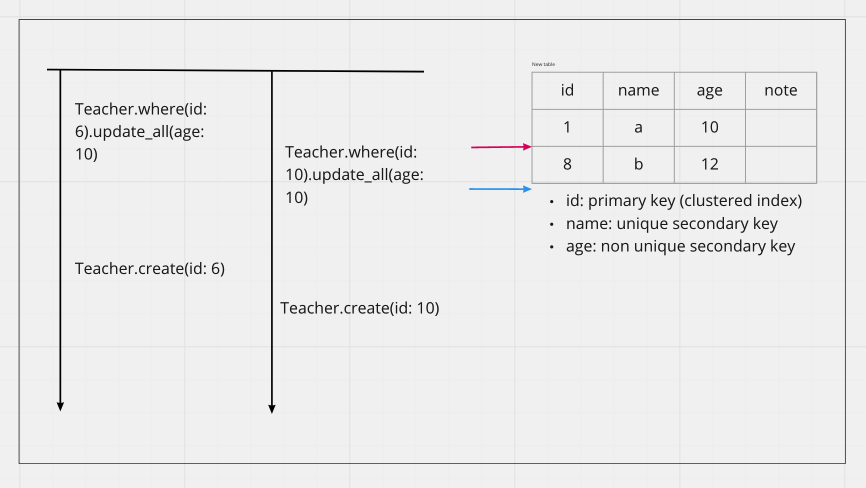
4. 範圍查詢:鎖定找過的每筆資料即使條件不合
接下來看一個 RR 蠻嚇人的一個特性,參考文件 15.7.2.1 Transaction Isolation Levels
“When using the default REPEATABLE READ isolation level, the first UPDATE acquires an x-lock on each row that it reads and
does not release any of them
也就是說 where condition 假使是範圍搜尋,RR 會把搜尋到的範圍全部鎖死,直到 transaction 結束!
讓我們看以下案例
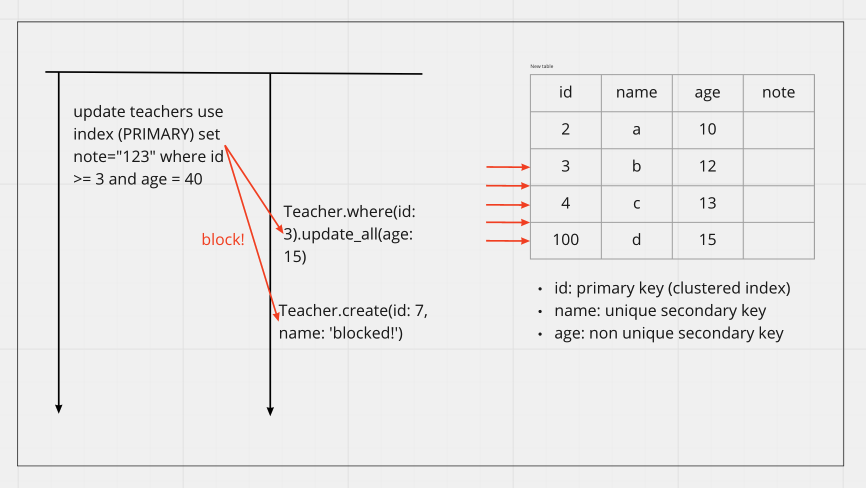
Update 的條件沒有命中但是全部都被 Lock,要 update / insert 都不行,相對的
RC 在檢查不符合條件就會 release,在做大規模的 Update / Delete 記得要用 RC 會比較好
Non Unique Index
上面的範例都是 Clustered Index,MySQL 支援 Secondary Index,其中 Unique Secondary Index 與 Clustered Index 行為類似,就不另外贅述,但是 Non Unique Index 要稍微留意
1. 查詢命中:依然會 Gap Lock
在一開始的範例,如果 Clustered Index 查詢有命中只會鎖那一行 (ex. update id = 1),但如果 Non Unique Index 即使完全命中,也會連同 Gap 一起鎖起來 (Next Key Lock)
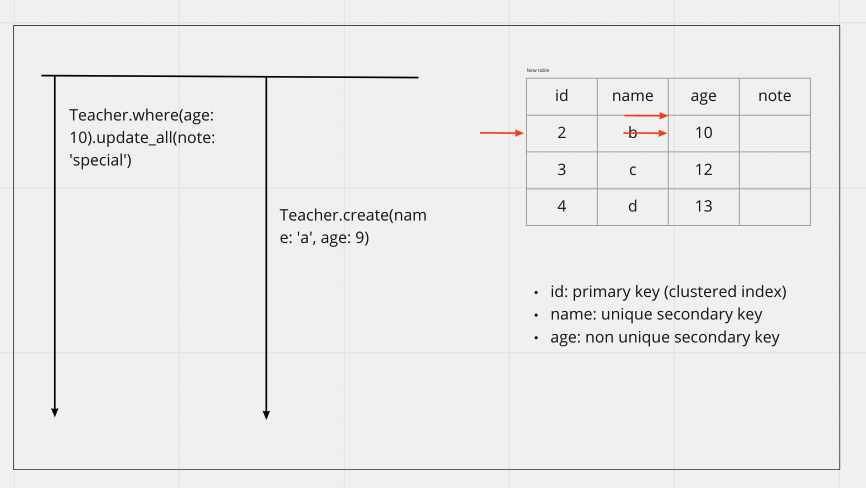 這邊 Lock 比較多,需注意 Secondary Index 會被鎖之外,對應的 Clustered Index 也會被鎖,這邊 age 鎖定 10 以及前面的區間,所以要插入 age: 9 就會失敗;運用上面的技巧,age 切換到不同區間就可以成功插入
這邊 Lock 比較多,需注意 Secondary Index 會被鎖之外,對應的 Clustered Index 也會被鎖,這邊 age 鎖定 10 以及前面的區間,所以要插入 age: 9 就會失敗;運用上面的技巧,age 切換到不同區間就可以成功插入
Foreign Key:會有 Share Lock
If a FOREIGN KEY constraint is defined on a table, any insert, update, or delete that requires the constraint condition to be checked sets shared record-level locks
更新欄位時 Foreign Key 也會被鎖住,之前有紀錄就不贅述 MySQL Deadlock 問題排查與處理
總結與建議
幾點建議
- 增加 Index 要仔細評估,Secondary Index 會造成寫入效能下降,體現於 lock 的使用
- 如果是用 ORM,記得檢查 Query
- 如果需要用 Secondary Index 改變欄位,建議可以用批次 (RoR 就是 find_in_batch)
- 或是先篩選出 Primary Key (預設 select 不會有 lock),再使用 Primary Key 當作修改條件避免 Gap Lock
沒事就用 Read Committed
進階:為什麼不要預設 Read Committed ?
既然 Repeatable Read 會有這麼多效能疑慮,更新時連 where 條件不符合的行都會鎖、還會有不預期的 Gap Lock,那為什麼預設不要改成 Read Committed ?
在 PostgreSQL 確實如此,PQ 9.3. Read Committed Isolation Level提到
The partial transaction isolation provided by Read Committed level is adequate for many applications, and this level is fast and simple to use
我在查閱 MySQL 相關資料,也有查到 Percona 一篇文章提及 MySQL 預設應該要改成 Read Committed 比較好 MySQL performance implications of InnoDB isolation modes
In general I think good practice is to use READ COMITTED isolation mode as default and change to REPEATABLE READ for those applications or transactions which require it.
那 MySQL 官方怎麼說,我找到一篇官方的 blog Performance Impact of InnoDB Transaction Isolation Modes in MySQL 5.7 建議到
- For short running queries and transactions, use the default level of REPEATABLE-READ.
- For long running queries and transactions, use the level of READ-COMMITTED
裡面有另一篇文做了 Benchmark 非常有趣 MySQL Performance : Impact of InnoDB Transaction Isolation Modes in MySQL 5.7,從 MySQL 內部的 Lock 數量與操做 QPS 衡量不同 isolation level,我本來以為 Read Committed 在增刪查改會碾壓 Repeatable Read,但發現盡然沒有,反而因為 Read Committed 在每次 Read 都會產生新的 MVCC 版本而有更多的內部 Lock,非常有趣
所以總結官方部落格建議,預設還是保留 RR 普遍效能反而更好,只有在長時間的 Job 再改成 RC 即可